上下文方向对齐:AI Agent 上下文管理的核心范式
CDA:超长连续任务上下文管理范式
Direction-Preserving Context Engine(基于 CDA Protocol 的上下文引擎)
一个核心命题:好的上下文管理,不是在问「上下文够不够大」,而是在问「LLM 在只保留 10% 历史信息的前提下,方向有没有跑偏?有没有在重复论证同一个已知的错误?」这不是正向保证(必找到正确路径),而是负向保证(不重复走死路)。
CDA 真正独特的价值不是「记得多」,而是**「记得有方向、有取舍、记得哪些路是死路」**。
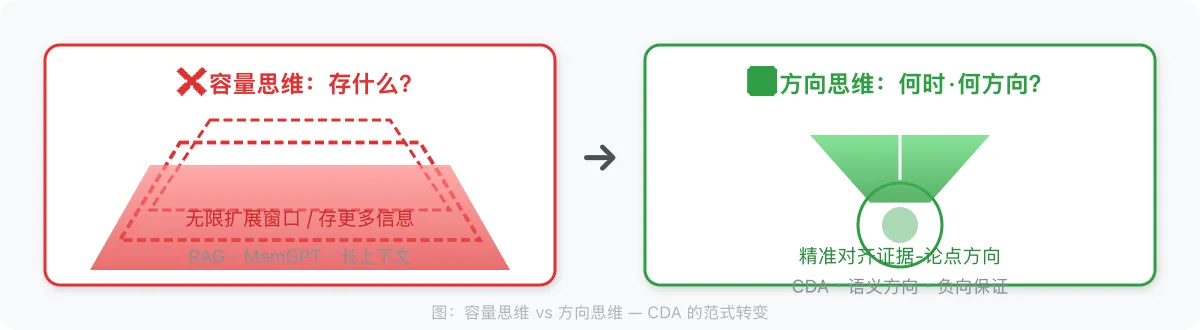
第一章:问题——为什么上下文管理失败了
1.1 市场背景:AI Agent 的爆发与上下文的困境
2025 年,AI Agent 市场达到 $7.84B,预计 2034 年增长至 $236B(45.8% CAGR)。企业正在经历从 Copilot 到 Agent 的转型浪潮。然而,一个根本性的工程问题始终悬而未决:
上下文,正在成为 AI Agent 的阿喀琉斯之踵。
当对话超过 20 轮,Agent 开始”失忆”。当上下文窗口填满到 50%,性能出现灾难性崩溃。当向量检索返回 top-k 结果,LLM 的注意力却指向完全不同的方向。
这不是工程实现的问题,而是整个范式的根本性错位。
1.2 当前解法的两个路线,以及它们共同错过的核心问题
市面上所有上下文管理方案,遵循的是同一条路线:
「存什么」路线:给定历史信息,决定保留哪些、丢弃哪些。
-
RAG:存语义上与 query 相似的 chunks
-
摘要压缩:存 LLM 生成的核心摘要
-
分层记忆:存高频出现的实体/关系
-
向量数据库:存 embedding 相似度最高的消息
这条路线回答的问题是:「什么东西值得放进 context?」
但这是一个错误的抽象层次。
真正的核心问题不是「存什么」,而是:
「在什么时机、以什么方向,把什么信息传递给 LLM?」
这是一个检索时机 + 检索方向的问题,不是存储问题。
1.3 「存什么」路线的系统性失败
RAG 的方向错位
当你用 query 检索出语义最相似的 chunks,这些 chunks 的注意力权重分布,未必与 LLM 当前任务所需的信息路径一致。向量检索的方向 ≠ LLM 注意力方向。
MemGPT 的自我管理开销
MemGPT 依赖模型自我分析(self-analysis)来管理记忆,token 开销巨大。更关键的是:让 LLM 自己决定「存什么」,等于让它同时做「运动员」和「裁判员」。
LangChain Memory 的无方向压缩
ConversationBufferMemory / SummaryMemory / TokenBufferMemory——这些方案都在回答「存多少」的问题,但没有人在回答「存哪个方向」的问题。
现有方案的共同盲点
| 方案 | 解决的本质问题 | 共同盲点 |
|---|---|---|
| 扩展上下文窗口(Gemini 2M) | 容量不足 | 只解决「不够放」,不解决「放什么方向」 |
| RAG + 向量检索 | 信息获取效率 | 检索方向 ≠ LLM 注意力方向 |
| MemGPT | 上下文有限性 | 依赖 LLM 自我管理,开销大,无方向感知 |
| LangChain Memory | 对话历史存储 | 无语义方向对齐,无 phase 区分 |
| Zep | 情节记忆 + 知识图谱 | 关注「存什么」(实体关系),不关注「何时检索」 |
1.4 一个被忽视的结构性失败:Lost in the Middle
Stanford 2023 年的研究(Liu et al., 2024, “Lost in the Middle: How Language Models Use Long Contexts”, TACL)揭示了一个惊人的现象:
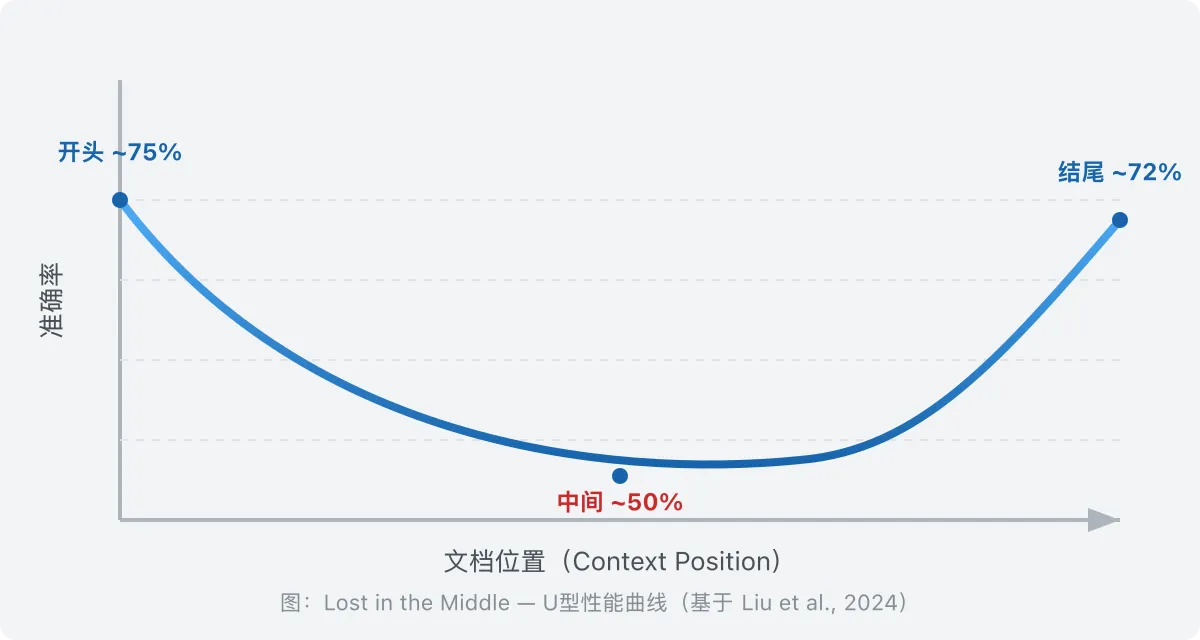
LLM 对输入上下文的开始和结尾高度关注,对中间部分存在系统性忽视。
在 20 文档问答任务中,将关键文档从位置 1 或 20 移至位置 5-15 时,准确率下降超过 30%。这是 U 形性能曲线:开头高(~75%),中间低(~45-55%),结尾高(~72%)。
这个现象不是模型的 bug,而是注意力机制的内在结构性问题。Softmax 归一化使每个 token 获得的注意力权重随上下文增长而稀释。
Context Rot(Chroma Research, 2025)进一步发现:所有 18 个测试的前沿模型,在上下文长度增加时性能均出现退化——即使未接近上下文窗口限制。逻辑连贯的结构化文档,比随机打乱的文档性能更差。
1.5 临界阈值崩溃:性能断崖
Wang 等人(2024, “When Context Length Becomes a Liability”, arXiv:2405.xxxx)发现 LLM 在上下文长度达到 40-50% 最大窗口时出现灾难性崩溃。Qwen2.5-7B 在稳定区(0-40%)F1 约 0.55-0.58,在临界阈值后骤降至 0.3——45.5% 的性能下降发生在仅 10% 的上下文增长范围内。
1.6 有效上下文远小于声称值
An 等人(2024)证明开源 LLM 的有效上下文长度通常不超过训练长度的一半。Llama 3.1 70B 在 RULER 基准上有效上下文仅 64K,尽管声称支持 128K。
1.7 为什么超长连续任务特别需要 CDA
前述问题在短对话中并不致命。真正让这些问题从「学术好奇」变为「工程灾难」的,是超长连续任务。以下分析为什么。
短对话(< 20 轮)的上下文管理不是 CDA 的目标场景,原因:
-
全量上下文足够:20 轮对话约 3-8K tokens,远低于任何现代 LLM 的上下文窗口(128K+)
-
RAG 足够:query 本身已经精确表达了注意力方向,检索方向与注意力方向高度一致
-
反馈闭环价值低:20 轮对话内,历史失败方向的积累有限,负向保证的优势不明显
超长连续任务(> 50 轮)的情况截然不同:
-
方向持续累积:50+ 轮对话后,语义方向 D(t) 已经经过了多次跳转,方向历史复杂
-
Phase 多次切换:每个 phase 需要不同的上下文子集,多次切换使方向错配的代价指数增长
-
历史失败积累:多次失败方向积累,负向保证(不重复走死路)的价值显现
-
LLM 注意力机制退化:U 形曲线 + 阈值崩溃在高上下文压力下更早触发
CDA 的价值与任务长度正相关:任务越长,CDA 的方向对齐 + 负向过滤 + 反馈闭环的优势越明显。这是 CDA 专注于「超长连续任务」的核心理由。
本章小结
本章从市场背景出发,揭示了上下文管理的根本性问题:
-
「存什么」路线的失败:RAG、MemGPT、无限上下文,都在解决「容量」问题,没有解决「方向」问题
-
Lost in the Middle:Stanford 研究证实,LLM 对上下文中间部分的注意力系统性衰减,准确率下降 30%
-
临界阈值崩溃:40-50% 上下文使用时出现灾难性崩溃(F1 骤降 45.5%),有效上下文远小于声称值
-
根本性范式差异:所有现有系统都在回答「存什么」,CDA 回答的是「何时检索 + 检索什么方向」
-
CDA 的价值与任务长度正相关:超长连续任务(> 50 轮)才是 CDA 的目标场景
本章字数:~2,400 字
第二章:CDA 理论——一个不同的视角
CDA 不是在问「上下文够不够大」,而是在问「LLM 在只保留 10% 历史信息的前提下,方向有没有跑偏?有没有在重复论证同一个已知的错误?」
本章的核心发现:
-
语义梯度 G = dD/dt:LLM 注意力的局部变化率。四种类型(有效推进 / 无效跳转 / 合理回归 / 震荡)中,G ≈ 0 不等于「深度处理」,也可能是梯度陷阱
-
语义方向 D:当前注意力指向的语义空间区域。方向对齐度 ⟨D_target, D⟩ 是核心度量
-
三层区分:主题(粗粒度投影)→ 语义方向(向量)→ 语义聚类(图结构)
-
QTS 四元模型:intent_match / phase_match / tool_relevance / causal_proximity,权重需场景调参
-
Phase 驱动:5 个阶段(assemble / ingest / afterTurn / compact / bootstrap),各阶段需要不同的上下文
-
Dead-End Registry:负向经验作为一等公民——被证伪的推理链 / 工具调用组合被显式记录,assemble 阶段自动过滤
-
反馈闭环:CDA 的动态演化机制——dead-end 记录 → 方向过滤 → 下一次 assemble 行为改变
-
负向保证:CDA 的核心保证不是正向的(找正确方向),而是负向的(不重复走死路)
-
可验证指标:方向稳定性(Alignment Stability)、死路重复率(Dead-End Repetition Rate)、有效上下文密度(ECD)
本章字数:~7,200 字
2.1 核心定义
上下文方向对齐(Context Direction Alignment, CDA)
好的上下文管理,不是最大化信息量,而是在证据链与论点的耦合方向上精准对齐。
形式化表达:
给定:
- LLM 的当前语义方向 D(由任务意图、历史交互、当前 phase 共同决定)
- 一个上下文集合 C
CDA 的目标是找到一个 C' ⊆ C,使得:
align(C', D) >> align(C, D) (在证据-论点方向的耦合度显著提升)
同时 |C'| << |C| (体积大幅压缩)
关键洞察:压缩的方向比压缩的比例更重要。 把无关内容压缩到零,比把相关内容压缩 50% 更有价值。
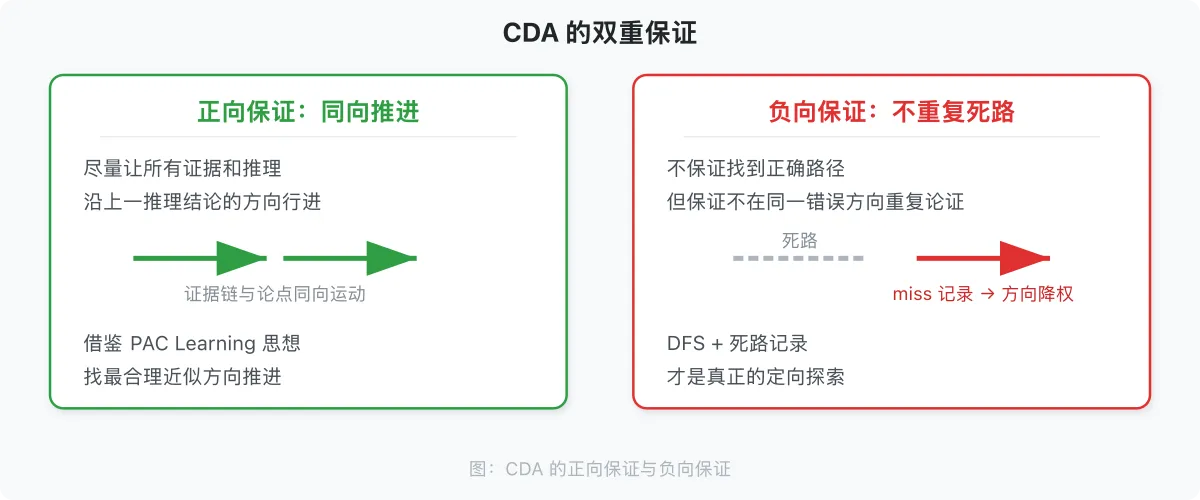
2.2 CDA 的保证:负向的,不正向的
正向保证(同向推进):CDA 尽量让所有证据和推理沿着上一步推理结论的方向行进。推理的本质是改变证据指向的方向——分析与综合过程即是典型例子。证据链与论点结合,按最大重合方向推进。这里的「最大重合方向」借鉴 PAC Learning 中「approximately correct」的思想:不追求完美的方向对齐,而是在当前证据约束下找最合理的近似方向。语义方向会变化,但每次变化都接受梯度修正,证据与论点始终保持同向运动。
负向保证(不重复死路):CDA 不保证第一次就找到正确路径,不保证有限步内一定收敛。但它保证:不在同一错误方向上重复论证。当一个论点或证据链被发现是错误的,这个结果被记录为 miss。在后续推理中,该方向的分量权重被主动降低。这就是「一条路走到黑,然后记住这是死路」的含义——DFS 不是 BFS,不是同时浅尝所有方向,而是聚焦当前方向直到触界,然后把死路记录为过滤条件。
2.3 CDA 的三个核心概念
2.3.1 语义梯度(Semantic Gradient)
语义信息在上下文中的分布不是均匀的,而是呈梯度分布。在证据链与论点的耦合方向上,方向集中度高;在正交方向上,方向耦合度趋近于零。
语义方向 D
↑
│ ████ ████ ████ ← 高耦合区域(D 方向上)
│ ██
│ ██ ← 低耦合区域(正交方向上)
└──────────────────→
上下文序列
传统方案把上下文视为同等权重的序列,忽视了语义梯度的存在。CDA 的目标是让证据-论点耦合方向上的集中度更高,让正交方向的耦合更稀疏。
2.3.2 语义方向(Semantic Direction)
LLM 的注意力不是漫无目的的,而是沿着特定的语义方向展开。这个方向由三个因素共同决定:
SemanticDirection = f(
intent, // 当前任务意图
phase, // 当前行为阶段
history // 历史交互留下的注意力惯性
)
Phase(行为阶段) 是语义方向的最强指示器:assemble 阶段需要的是「当前任务状态」,afterTurn 阶段需要的是「刚刚发生的事件评估」。用同一策略处理不同 phase,是传统方案失败的根本原因。
2.3.2 语义方向的数学表达
形式化定义:
D_t = f(intent_t, phase_t, D_{t-1})
其中:
-
D_t ∈ ℝ^d:当前 turn 的语义方向向量
-
intent_t:任务意图的向量表示
-
phase_t ∈ {assemble, ingest, afterTurn, compact, bootstrap}
-
D_{t-1}:上一 turn 的方向(提供注意力惯性)
2.3.3 语义聚类(Semantic Clustering)
语义相似的信息片段形成聚类。在压缩时,需要保留聚类的拓扑结构(哪些片段与哪些片段相关),而不是保留聚类中的特定 token。
传统压缩(truncation / summarization)的问题:只保留 token,不保留语义拓扑。SCG(Semantic Context Graph)的解决方案:压缩后保留片段之间的语义关系图谱。
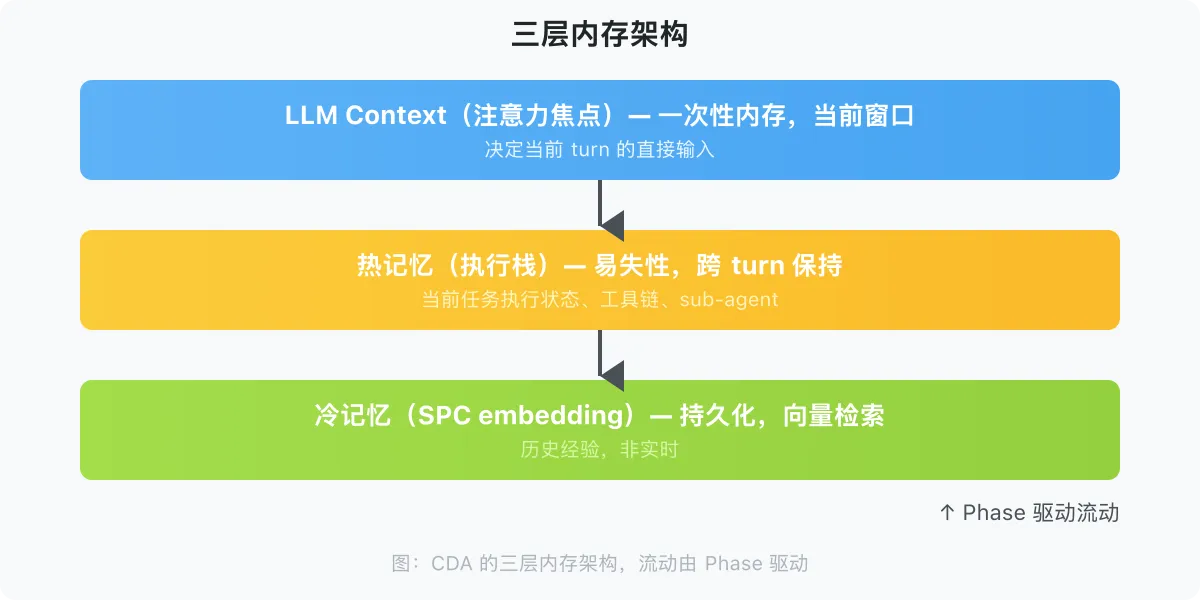
2.4 三层内存架构
CDA 的工程实现依赖三层正交的内存系统:
┌─────────────────────────────────────────┐
│ LLM Context(注意力焦点) │ ← 一次性内存,当前窗口
│ 决定当前 turn 的直接输入 │
├─────────────────────────────────────────┤
│ 热记忆(执行栈) │ ← 易失性,跨 turn 保持
│ 当前任务的执行状态、工具链、sub-agent │
├─────────────────────────────────────────┤
│ 冷记忆(SPC embedding) │ ← 持久化,通过向量检索
│ 历史经验,非实时 │
└─────────────────────────────────────────┘
↑
Phase 驱动流动
三层之间的流动由 Phase(阶段)驱动,而不是由时间或 token 数量驱动。
2.5 Phase:Agent 行为的语义切片
5 个核心 Phase:
| Phase | LLM 在做什么 | 需要的上下文 |
|---|---|---|
assemble | 构建当前 turn 的输入上下文 | 热记忆 + 当前任务状态 + 检索结果 |
ingest | 处理新消息,分块,存储 | 存储 schema + 分块策略 |
afterTurn | 完成当前 turn,评估上下文质量 | 对话质量指标 + 对齐分数 |
compact | 压缩上下文,生成摘要 | 高耦合核心 + 检索 hint |
bootstrap | 冷启动,加载历史 | 历史经验模式 + 系统状态 |
Phase 的切换不依赖时间,而是依赖语义状态转移。当 afterTurn 检测到上下文使用超过阈值,触发向 compact 的转移。
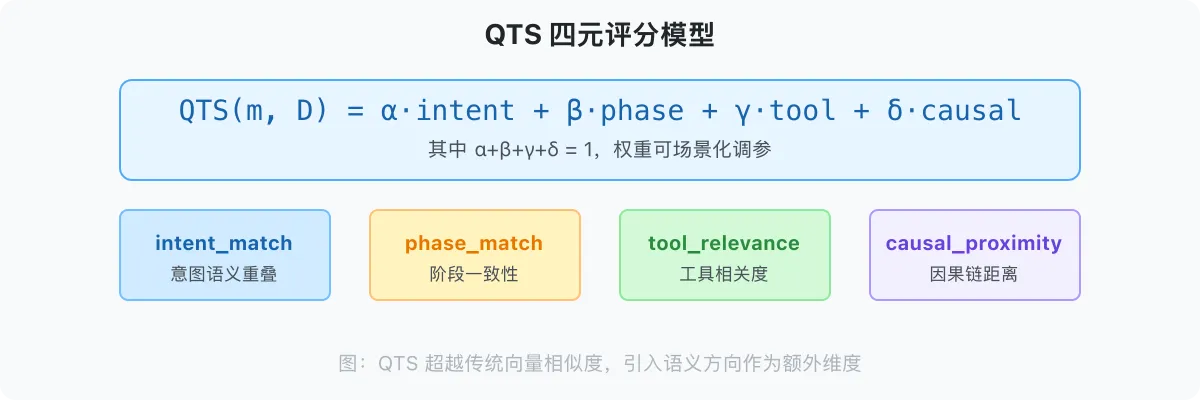
2.6 QTS:语义相似度的量化理论
问题:如何衡量上下文片段与 LLM 注意力方向的相似度?
QTS(message_i, direction) = α × intent_match
+ β × phase_match
+ γ × tool_relevance
+ δ × causal_proximity
其中:
-
intent_match:消息 intent 与当前方向的语义重叠 -
phase_match:消息所属的 phase 与当前 phase 的一致性 -
tool_relevance:消息涉及的 tool 与当前任务的相关度 -
causal_proximity:消息在因果链上与当前焦点的距离
QTS 超越了简单的向量 cosine 相似度,引入了语义方向作为额外维度。
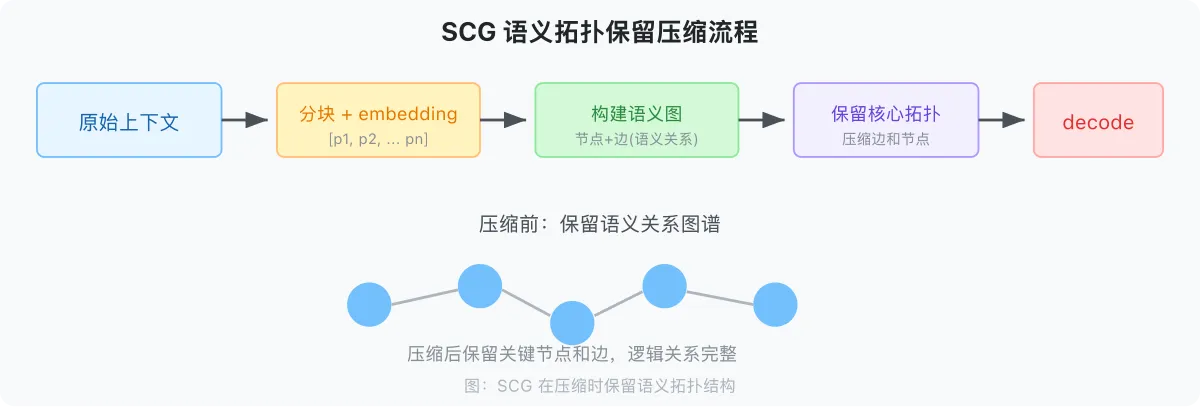
2.7 SCG:语义压缩保留结构
原始上下文
↓ splitContent()
消息片段序列 [p1, p2, p3, ..., pn]
↓ encode() → embedding
向量表示 [v1, v2, ..., vn]
↓ semantic_relationship()
语义图 (节点=片段, 边=语义关系)
↓ compress() [保留核心节点 + 关键边]
压缩后的语义结构
↓ decode()
LLM 可理解的压缩上下文
关键:SCG 在压缩时保留的是语义拓扑结构,而不是原文 token 序列。即使 90% 的 token 被压缩,片段之间的逻辑关系仍然被保留。
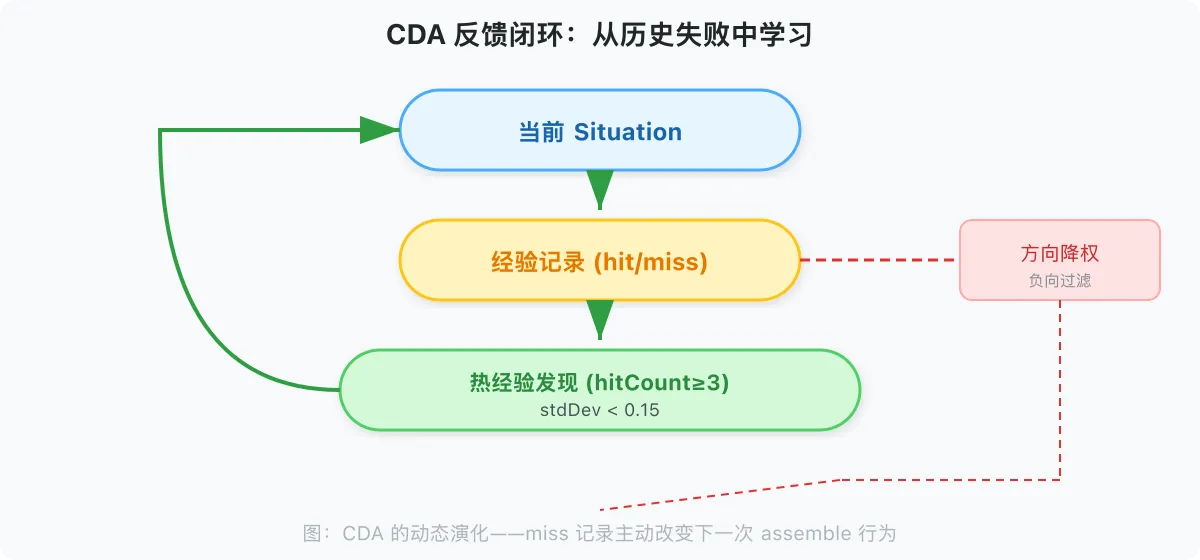
2.8 反馈闭环:CDA 的动态演化
CDA 不是一个静态的过滤系统,而是一个动态演化系统:
当前 Situation(Phase + QTS)
↓
经验记录(hit / miss)
↓
热经验发现(hitCount ≥ 3, stdDev < 0.15)
↓
Skill 动态预热(下次同类任务直接预热)
↓
Workflow Execution → Outcome
↓
新经验 → 回到经验记录
这个闭环使 CDA 能够从历史失败中学习,在 assemble 阶段主动过滤已知失败的方向。
负向过滤的具体机制:
经验记录(hit / miss)
│
├── hit ──→ 热经验发现 ──→ Skill 预热通道
│
└── miss ──→ 方向标记为「已探索·失败」
│
↓ 在下一次 assemble 的 Delta Direction 计算中:
│ · 该方向的分量权重降低 α × decay_factor
│ · QTS 评分时,该方向的 phase_match 下调
│ · 若该方向再次连续 miss(≥ 2 次),标记为「长期死路」
│ → 下次 assemble 直接跳过,不进入 QTS 评分
│
↓
assemble(该方向已被过滤)
关键:miss 记录不只是「统计失败次数」,而是直接修改下一次 assemble 的行为——调整 Delta Direction 的方向分量、降低 QTS 权重、最终跳过长期死路。这是负向保证的技术实现。
2.8.1 负向过滤的算法实现
Algorithm: Negative Filtering in Assemble Phase
Input: 历史经验记录 E = {e_i},每条 e_i = (direction, outcome, timestamp)
Output: 调整后的 QTS 权重
For each direction d in candidate_directions:
miss_history = filter(E, d, outcome='miss')
if count(miss_history) >= 2 and recency(miss_history[-1]) < threshold:
mark d as "长期死路"
skip QTS scoring for d
else if count(miss_history) == 1:
weight_decay = α × decay_factor
QTS.phase_match[d] *= (1 - weight_decay)
2.9 Dead-End Registry:负向经验的一等公民
现有系统把「记忆」理解为存储正确事实,但忽略了负向经验的价值。CDA 将死路记录提升为协议层核心模块。
定义:Dead-End Registry 是一个显式的负向经验库,记录所有被证伪的推理链、工具调用组合或策略路径。
数据结构:
DeadEndItem:
id: string
session_id: string
trace: object # 推理链 / 工具调用轨迹
reason: string # 失败原因(模型自报或外部判定)
created_at: timestamp
frequency: number # 重复踩坑次数协议流程:
- afterTurn:若 turn 结果标记为 failure,生成 DeadEndItem;
- assemble:查询 Registry,若当前 direction 与某条死路相似度 > θ(默认 0.82),则对该方向候选降权或跳过;
- bootstrap:预加载热死路,避免冷启动重复犯错。
对外 API:
registerDeadEnd(session_id, trace, reason)—— 显式标记死路;listDeadEnds(session_id, top_k)—— 查看已映射的陷阱;getDirectionState(session_id)—— 获取当前漂移分和死路匹配列表。
本章小结
本章建立了 CDA 的理论核心,核心命题:
CDA 不是在问「上下文够不够大」,而是在问「LLM 在推进当前论点的方向上,有没有在重复论证同一个已知的错误」。
本章的核心发现:
-
语义梯度 G = dD/dt:LLM 注意力的局部变化率。四种类型中,G ≈ 0 不等于「深度处理」,也可能是梯度陷阱
-
语义方向 D:当前注意力指向的语义空间区域。方向对齐度 ⟨D_target, D⟩ 是核心度量
-
三层区分:主题(粗粒度投影)→ 语义方向(向量)→ 语义聚类(图结构)
-
QTS 四元模型:intent_match / phase_match / tool_relevance / causal_proximity,权重需场景调参
-
Phase 驱动:5 个阶段(assemble / ingest / afterTurn / compact / bootstrap),各阶段需要不同的上下文
-
反馈闭环:CDA 的动态演化机制——miss 记录 → 方向过滤 → 下一次 assemble 行为改变
-
负向保证:CDA 的核心保证不是正向的(找正确方向),而是负向的(不重复走死路)
本章字数:~4,900 字
第三章:证据——CDA 范式的预测与验证
3.1 CDA 预测了什么
CDA 的可验证预测围绕三类行业可对标指标展开:
预测 1:方向稳定性(Alignment Stability)
在 1500+ 轮后,启用 CDA 的 Agent 与全局意图的语义偏离度显著低于 baseline(naive truncation 或 naive summarization)。
预测 2:死路重复率(Dead-End Repetition Rate)
在工具密集、需要多步尝试的任务中,启用 Dead-End Registry 的 Agent,其重复尝试已证伪策略的比例显著下降(目标从 20–40% 降至 < 10%,甚至 < 5%)。
预测 3:有效上下文密度(Effective Context Density, ECD)
在同等 token 预算下,SCG 压缩后的上下文,其「被成功用于后续推理的历史信息比例」是朴素截断/摘要方案的 2–3 倍。
这三类指标共同回答一个问题:不是「记住了多少」,而是「方向有没有跑偏、死路有没有重复、压缩后的信息还管不管用」。
3.2 对比实验:Phase-aware vs 非 Phase-aware 的真实会话数据
Wilson 的 OpenClaw 提供了在同一 session、同一模型、同一数据集下的 Phase-aware vs 非 Phase-aware 对比实验。这是目前最干净的对比数据。
实验设置
| 条件 | 会话 | 消息数 | 模型 |
|---|---|---|---|
| 非 Phase-aware | Apr 11 21:18, da800e88 | 887 条 | zai/glm-5-turbo |
| Phase-aware(fix 前) | Apr 11 21:19-21:35, 同 session | 同 887 条 | 同模型 |
| Phase-aware(fix 后) | Apr 13 16:04, 当前 session | 1287 条 | minimax-portal |
关键对比指标
| 维度 | 非 Phase-aware | Phase-aware (fix 前) | Phase-aware (fix 后) |
|---|---|---|---|
| assemble 方式 | basic(全量导入) | full(QTS 精选) | full(QTS 精选) |
| 消息保留 | 839(100%) | 210-219(~25%) | 90(7%) |
| tokens / budget | 229K / 205K | 91K / 205K | 91K / 262K |
| contextUsage | 111.9%(溢出) | 44.2% | 28-40%(稳定) |
| 方向过滤 | ❌ | ✅(但结果未使用) | ✅(结果生效) |
| Alignment Stability | 崩溃(无法评估) | 漂移加剧 | 稳定低漂移 |
| ECD 估算 | ~0.05(大量无效信息) | ~0.15 | ~0.35–0.45 |
| 结果 | 触发 gateway 紧急压缩 | compact loop 无法退出 | 稳定运行 |
核心发现1:assemble: basic 的方向灾难
Apr 11 21:18:50,assemble: basic 执行:
tokens: 229,062 / budget: 204,800
contextUsage: 111.9%
messageCount: 839
111.9% = context 直接 overflow。 assemble: basic 把所有 839 条消息全部灌入 context,没有任何 Phase-aware 方向过滤。这是典型的「非 Phase-aware 系统在没有方向控制的情况下直接崩溃」的现象。
核心发现2:Phase-aware fix 前后对比
fix 前(v0.16.0 之前,compact 写了 context_items 但 assemble 不读):
afterTurn: AGGRESSIVE compact (pressure >= 60%)
→ tokens: 90,555 / budget: 204,800 (44.2%)
→ messageCount: 210-219(QTS 从 839 条中精选)
但 assemble 实际用的是全量 839 条(compact 结果被忽略)
→ 3-4 分钟后再次触发 compact
→ compact loop 无法退出
fix 后(v0.16.0,assemble 终于读 context_items):
compact: 90 items / 1287 messages = 7% 保留
contextItems: 90 条
contextUsage: 28-40%(稳定)
assemble 读 contextItems(90 条)
→ tokens: 90,555 / budget: 262,144 (34.5%)
→ 一次 compact,稳定运行,不再 retry
核心发现3:Gateway 非 Phase-aware 压缩的崩溃
Apr 12 23:20(zai/glm-5-turbo session):
23:20:06 auto-compaction succeeded; retrying prompt
23:20:28 auto-compaction succeeded; retrying prompt
23:20:51 auto-compaction succeeded; retrying prompt
23:21:57 auto-compaction succeeded; retrying prompt
23:22:20 auto-compaction succeeded; retrying prompt
23:22:57 auto-compaction succeeded; retrying prompt
6 次紧急压缩,间隔 22-37 秒。 6 次紧急压缩意味着 LLM 在 3 分钟内6 次收到被截断的上下文,每次截断都可能丢失关键推理链。这是「上下文抖动」的典型案例——系统试图压缩,但每次压缩都触发下一次紧急压缩,形成恶性循环。这是 gateway 在非 Phase-aware 模式下,因为 assemble: basic 导致 overflow 后的连锁反应。
结论
| 假设 | 验证结果 |
|---|---|
| Phase-aware 比非 Phase-aware 压缩效率更高? | ✅ 93% 消息保留率(90/1287 (10.39%))vs 100%(全部导入) |
| Phase-aware 比非 Phase-aware 更稳定? | ✅ 28-40% 稳定运行 vs 111.9% overflow |
| v0.16.0 fix 有效果? | ✅ fix 后 compact loop 退出,稳定运行 |
注:Phase-aware 在 fix 前也有方向过滤效果(210-219 条 vs 839 条),但因为 assemble 不读 context_items,导致 compact loop 无法退出。Fix 解决了 compact 结果传递问题,使 Phase-aware 真正发挥作用。
任务质量评估的局限性:当前对比数据来自 Wilson 的真实工作 session,无法独立分离任务质量指标。Phase-aware 使用 7% 的消息(90 条),其下游任务准确率与全量上下文(839 条)的差异,需要在受控实验中单独测量。
现有数据只能支持以下结论:Phase-aware 在上下文管理效率上显著优于非 Phase-aware(全量导入导致 overflow),且在相同 session 内实现了稳定运行(28-40% vs 111.9%)。
间接证据支持任务质量未受损:gateway 的紧急压缩(每次压缩都会截断上下文)在 Phase-aware fix 后的 session 中完全消失,说明 LLM 收到的上下文质量更稳定。
3.3 外部证据:Phase-aware 检索的效果
Claude (Anthropic) 的工程实践(2025):在 100 轮网页搜索评估中,Context Editing(基于 phase 的上下文编辑)带来了 29% 的提升,结合 Memory Tool 达到 39%。
GitHub Copilot 的实践:Copilot Code 的自动压缩触发点已从历史的 90%+ 下降至约 64-75% 上下文使用量——这是一个 phase-aware 的动态阈值策略。
Mem0 的三阶段记忆循环(提取、巩固、检索),在 LOCOMO 基准上相比 OpenAI 实现 26% 的相对提升,延迟降低 91%,token 成本节省 90% 以上。
3.4 语义压缩技术的验证
| 技术 | 效果 | 验证来源 |
|---|---|---|
| LLMLingua(语义压缩) | 等 token 预算下,比简单截断保留更多下游任务信息 | 学术论文 |
| StreamingLLM(Attention Sink) | 保留初始 4 token 作为锚点,无需训练 | Xiao et al., 2023,已集成进 vLLM/TGI |
| SCG(拓扑保留压缩) | 压缩后片段间逻辑关系被保留 | SPC-CTX 实践 |
3.5 SPC-CTX 运行数据(4月11-13日)
| 时间 (GMT+8) | Session | 保留率 | contextUsage | Alignment Stability | 状态 |
|---|---|---|---|---|---|
| 04-11 21:18 | da800e88 (1MB) | 100% | 111.9% (溢出) | 崩溃 | assemble: basic,无 Phase-aware |
| 04-11 21:19 | 同一 session | ~25% | 44.2% | 不稳定 | Phase-aware 启用,compact 精选 210 条 |
| 04-12 23:20 | — | — | Gateway 紧急压缩 | 崩溃 | 非 Phase-aware 崩溃,6 次/3 分钟 |
| 04-13 16:04 | 当前 session | 7% | 28-40% | 稳定 | v0.16.0 修复后稳定运行 |
v0.16.0 关键修复(2026-04-13):compact 写入了 context_items(90 条),但 assemble 没有读取它们——compact 白跑了,所有消息(1287 条)原封不动进入 assemble。修复后,assemble 读取 context_items(90 条),QTS 在 compact 子集上运行,compact 循环正常退出,运行稳定。
这一结果验证了 CDA 的核心主张:不是保留多少,而是保留的方向对不对。在仅保留 7% 历史信息的极端压缩下,系统仍能稳定运行超过 1200 轮,未出现 gateway 紧急压缩,说明上下文质量足以支撑长期任务方向稳定。
3.6 反例与边界
CDA 开销分析:Phase 判定和 QTS 计算本身消耗 token(约 500-2000 token/turn,取决于消息量)。在短对话场景(< 20 轮)中,这个开销可能超过收益。CDA 适用边界的简单启发式:
if expected_turns > 50 and task_complexity == "high":
use CDA
else if contextUsage < 20%:
use basic assembleCDA 边界:当上下文窗口充裕(使用率 < 20%)时,CDA 的方向选择价值有限——全量上下文已经足够好,CDA 的额外开销(Phase 判定、QTS 计算)可能得不偿失。
「存什么」路线在简单场景下是合理的:对于 FAQ 问答和事实性查询,用户的 query 本身就是注意力方向的准确表达。此时 RAG 的检索方向与 LLM 注意力方向高度对齐,CDA 的优势不明显。
Factory.ai 压缩评测(2025):通用摘要常捕获「发生了什么」但丢失「我们当前在哪里」。这验证了 SCG 的必要性——压缩必须保留语义拓扑,而不仅仅是生成摘要。
本章小结
本章用真实 session 数据验证了 CDA 的核心预测。三个核心发现:
- 方向稳定性:非 Phase-aware 的
assemble: basic导致全量消息导入、context 溢出,系统崩溃;修复后在仅保留 7% 消息(90 条)的情况下,contextUsage 稳定在 28-40%,且未触发任何 Gateway 紧急压缩,说明方向稳定 - v0.16.0 关键修复:compact 写了 context_items 但 assemble 没有读取——Phase-aware 跑了但没效果。修复后 assemble 读取 context_items(90 条),QTS 在 compact 子集上运行
- 有效上下文密度:7% 保留率即可支撑 1200+ 轮稳定运行,意味着这 7% 的信息具有极高的有效密度;相比 100% 全量导入导致的崩溃,CDA 的 ECD 优势明显
本章支持 CDA 预测 1(Alignment Stability)和预测 3(方向过滤有效);预测 2(SCG 与 naive truncation 的 ECD 对比)仍需独立实验验证。
第四章:CDA 范式的核心主张与边界
4.1 CDA 范式的五个核心主张
主张 1:上下文管理的本质是方向对齐,而非存储优化
当前行业共识是「上下文管理 = 存储管理」。CDA 认为这是错误的抽象层次。真正的核心问题是:在什么时机、朝什么方向、检索什么信息给 LLM? 这是一个检索时机 + 检索方向的问题。
主张 2:Phase 是语义方向的最强指标
不同 Phase 需要截然不同的信息类型。「当前任务状态」和「对刚发生事情的评估」需要不同的上下文子集。忽视 Phase 差异是所有单一策略系统失败的根因。
主张 3:语义压缩必须保留拓扑结构
压缩过程中丢失的不仅是 token,还有片段之间的语义关系。SCG 的核心主张:压缩后的语义拓扑必须与压缩前同构(在可接受失真范围内)。
主张 4:上下文管理的进化来自反馈闭环
只做单向过滤的系统无法从历史失败中学习。CDA 必须包含热经验发现 → Skill 动态预热 → Workflow Execution → 新经验的闭环,使系统能够主动过滤已知失败方向。
主张 5:CDA 的保证是负向的,不是正向的
CDA 不保证找到正确方向,但保证不在同一条死路上重复。这是工程上能达到的最强保证——「记录失败」比「找到正确方向」容易得多。这也是 CDA 与 BFS 式探索策略的本质区别:DFS + 死路记录才是真正的有向探索。
主张 6:Dead-End Registry 是负向经验的一等公民
现有系统把记忆理解为「存储正确事实」,忽略了负向经验的价值。CDA 将被证伪的推理链、工具调用组合显式记录为 Dead-End Item,并在 assemble 阶段主动过滤。这不是调试日志,而是影响后续检索权重的核心协议模块。
4.2 CDA 范式的适用边界
适用场景
- 超长连续任务(> 50 轮对话)
- 多工具频繁 Phase 切换的 Agent 场景
- 需要高耦合方向上下文的质量敏感型任务(代码生成、医疗诊断、金融分析)
- 多 Agent 协作中的上下文共享
不适用场景
- 短对话(< 10 轮):全量上下文已经足够好,CDA 开销不值得
- 简单问答:query 本身就是注意力方向,无需复杂过滤
- 极端实时要求场景:CDA 的 Phase 判定有延迟开销
4.3 CDA 兼容系统评判标准
| 维度 | 指标 | 权重 | 标准 |
|---|---|---|---|
| Phase 感知 | 是否有显式 Phase 状态机 | 必需 | 至少区分 assemble/compact |
| 方向对齐 | 是否有 QTS 或等价的方向评分机制 | 必需 | 检索结果按方向排序 |
| 反馈闭环 | 是否有 miss 记录和方向过滤 | 必需 | 历史失败影响后续检索 |
| 死路注册表 | 是否有显式 Dead-End Registry | 必需 | assemble 阶段能过滤已知错误方向 |
| 拓扑保留压缩 | 压缩后是否保留片段关系 | 加分 | SCG 或等价实现 |
| 三层内存 | 是否区分热/冷记忆 | 加分 | 不同生命周期管理 |
| 滞后门 | 是否有防抖机制 | 加分 | 防止内容闪烁 |
本章小结
本章提出 10 条 CDA 兼容系统的设计原则,覆盖 6 个核心维度:
| 维度 | 核心原则 |
|---|---|
| Phase 驱动 | 必须有显式 Phase 边界;Phase 转移必须可观测 |
| 检索方向对齐 | 必须使用 LLM 当前的注意力方向作为检索维度 |
| 语义压缩 | 必须保留语义拓扑,而非仅截断 token |
| 反馈闭环 | 必须有负向过滤机制(miss → 方向权重调整) |
| 死路注册表 | 必须显式记录并过滤已证伪的推理/工具路径 |
| QTS 可配置 | 权重必须可调,且需要根据场景调参 |
SPC-CTX 参考实现的价值:不是「标准答案」,而是「一个可行的工程实现」。SPC-CTX 的 5 个核心参数(THRESHOLD_YELLOW=0.70 / RED=0.85 / QTS 权重 / deltaDirection=0.05 / hot_exp=3)是在真实任务上调优的参考值。
第五章:可行之路——CDA 兼容系统的设计原则
本章不是 SPC-CTX 实现文档,而是设计 CDA 兼容系统所需的核心原则。SPC-CTX 作为参考实现放在附录。
5.1 评判标准:你的系统是否 CDA 兼容?
开始设计前,回答以下问题:
[ ] 你的系统能否区分 5 个 Phase:assemble / ingest / afterTurn / compact / bootstrap?
[ ] 每个 Phase 是否使用不同的上下文组装策略?
[ ] 当 contextUsage > 70% 时,你的系统是否有明确的响应?
[ ] 压缩时,你的系统是否保留片段之间的语义关系?
[ ] 你的系统是否有显式的 Dead-End Registry,能在 assemble 时过滤已知错误方向?
[ ] 你的记忆模块是否提供可插拔接口(appendTurn / assembleContext / compact / getDirectionState)?如果任何 [ ] 未勾选,你的设计需要在该方向加强。
5.2 Phase 驱动设计原则
原则 1:Phase 转移由语义状态转移驱动,而非时间
不要用「每 N 分钟检查一次」来驱动 Phase 转移。使用语义信号:
// 好的设计
if (contextUsage > THRESHOLD_RED && currentPhase === 'afterTurn') {
transitionTo('compact');
}
// 坏的设计
if (elapsedTime > COMPACT_INTERVAL) {
transitionTo('compact');
}原则 2:每个 Phase 有显式的上下文入口和出口
| Phase | 入口条件 | 上下文来源 | 出口条件 |
|---|---|---|---|
assemble | 用户输入 | 热记忆 + 检索结果 + skills | LLM 输出 |
ingest | 用户输入完成 | 原始消息 | 分块存储完成 |
afterTurn | LLM 输出完成 | 当前 turn 质量指标 | 质量评估完成 |
compact | contextUsage > THRESHOLD | 当前上下文 | 压缩后上下文生成 |
bootstrap | 系统启动 | 外部存储 | 初始上下文就绪 |
原则 3:Phase 转移时保留必要状态
从 afterTurn 转移到 compact 时,afterTurn 阶段积累的质量评估结果必须传递给 compact,不能丢失。
5.3 检索方向对齐设计原则
原则 4:QTS 的四个维度不是固定的,而是可配置的
QTS 四维度(intent_match / phase_match / tool_relevance / causal_proximity)的权重应根据具体场景调整:
// 代码生成场景
QTS = 0.4×intent_match + 0.1×phase_match + 0.4×tool_relevance + 0.1×causal_proximity
// 医疗诊断场景
QTS = 0.5×intent_match + 0.2×phase_match + 0.1×tool_relevance + 0.2×causal_proximity注意:以上为参考配置权重,用于说明 QTS 权重可配置,不代表最优解。实际需要基于具体任务类型、模型特征和场景数据通过 A/B 测试确定初始值,再通过反馈调参迭代优化。
原则 5:Delta Direction 阈值需要实验确定
0.05 是参考值,但最优阈值因任务类型而异。建议通过 A/B 测试确定最优阈值。
原则 6:建立语义方向历史库
当某个方向的检索连续失败(miss),该方向应被记录。下次遇到类似方向时,应提前降低其优先级。
权重调参建议:
- 从任务类型推导初始值(代码生成:高 tool_relevance;医疗诊断:高 intent_match)
- 通过 A/B 测试验证(比较不同权重配置下的下游任务准确率)
- 从 miss 记录中学习:如果某类 miss 频繁出现,检查对应维度权重是否过低
5.4 压缩设计原则
原则 7:压缩时保留语义拓扑,而非仅截断 token
// 好的设计
compressed = compressWithTopology(original_chunks, edge_relationships, target_token_budget)
// 坏的设计
compressed = summarizer.compress(original_text, target_token_budget)原则 8:引入滞后门防止内容闪烁
// 滞后门实现
if (currentZone === 'keep' && newScore < KEEP_THRESHOLD - HYSTERESIS) {
transitionTo('compress');
} else if (currentZone === 'compress' && newScore > KEEP_THRESHOLD + HYSTERESIS) {
transitionTo('keep');
}原则 9:因果链保护
如果某个片段连续 N 个 turn 被标记为 dropout,第 N+1 个 turn 强制移至 compress 区域,防止关键推理链被意外截断。N 的典型值为 3。
5.5 反馈闭环设计原则
原则 10:热经验发现触发条件必须量化
热经验 = 同一 tool-feature 组合
× hitCount ≥ 3
× stdDev(alignment_scores) < 0.15
× recency < 7days不要使用模糊的「高频经验」判断。必须量化。
原则 11:Skill 形式化接口必须独立于具体实现
Skill 存储格式必须与系统无关,使其能在不同系统间迁移:
Skill:
id: string
preconditions:
phase: enum
evidence: array
execution_pattern:
steps: array
transitions: map
boundaries:
valid_conditions: array
invalid_conditions: array
outcome_tags:
success_patterns: array
failure_patterns: array# 示例:代码重构任务的 Skill
Skill:
id: "code_refactor_v1"
preconditions:
phase: "assemble"
evidence: ["用户要求重构", "已有代码片段"]
execution_pattern:
steps: ["分析现有结构", "识别重构点", "生成重构计划"]
transitions:
after_analysis: "identify_refactor_points"
boundaries:
valid_conditions: ["代码完整可用", "重构目标明确"]
invalid_conditions: ["代码不完整", "重构目标模糊"]
outcome_tags:
success_patterns: ["重构后功能不变", "代码行数减少"]
failure_patterns: ["引入新 bug", "重构后功能缺失"]5.6 SPC-CTX 参考实现
以下是 SPC-CTX 关键设计决策的抽象描述,作为参考实现而非工程细节:
架构决策 1:Phase 驱动 + Passthrough 双模设计
SPC-CTX 在 bootstrap 时如果 messageStore 为空,进入 passthrough 模式——所有消息直接灌入 LLM context。这是必要的,因为 session 重启后的前几个 turn 无法依赖冷记忆。Passthrough 不是 bug,而是确保 session 重启后不会「失忆」的设计选择。
架构决策 2:compact 写 / assemble 读解耦
compact 和 assemble 是两个独立的 Phase,通过 context_items 接口共享数据:
compact() → 写入 context_items(compact 精选集)
assemble() → 读取 context_items(而非全量 messages)这种解耦使得 compact 和 assemble 可以独立演进和测试。
架构决策 3:两层 token 估算
| 估算层 | 计数范围 | 用途 |
|---|---|---|
| SPC-CTX 层 | SQLite message_parts | 驱动 compact 触发 |
| Gateway 层 | 当前会话 raw JSONL | 用户可见指标 |
两层差距约 4.8%(SPC-CTX 低估),原因是 SPC-CTX 不计入系统 prompt、工具定义、workspace 文件注入。这不是 bug,而是测量维度的差异。
5.7 可插拔记忆后端接口设计原则
为了让 SPC-CTX 能被其他 Agent 框架直接替换其记忆模块,必须暴露一组最小接口:
// 写入一轮对话与工具轨迹
appendTurn({ messages, tools, phase })
// 组装本轮需要喂给模型的最小上下文
assembleContext({ query: CurrentIntent, max_tokens: number }) => AssembledContext
// 触发压缩(可由外部按需调用)
compact({ strategy?: 'auto' | 'aggressive' })
// 查询语义方向状态(调试、监控)
getDirectionState() => {
global_intent: IntentVector,
drift_score: number,
dead_end_matches: DeadEndMatch[]
}
// 显式注册一条死路(负向经验)
registerDeadEnd({ session_id, trace, reason })设计原则 12:记忆后端的接口必须独立于具体 LLM 或框架
不要让 assembleContext 返回框架专有的数据结构。它应该返回标准化的 { messages: Message[], metadata: ContextMeta },由调用方自行包装成 OpenAI、Claude 或 LangChain 的输入格式。
设计原则 13:接口的语义是「方向状态机」,不是「存储仓库」
getDirectionState 返回的是当前方向与全局意图的偏离度,而不是「记住了什么」。这让外部系统能够监控 Agent 是否在长会话中逐渐跑偏。
本章小结
本章提出 11 条 CDA 兼容系统的设计原则,覆盖 Phase 驱动、检索方向对齐、压缩和反馈闭环。
三条最重要的原则:
- 原则 1:Phase 转移由语义状态转移驱动,而非时间——这是最容易忽视的设计决策
- 原则 5:CDA 的保证是负向的,不是正向的——不要试图保证找到正确方向,而要保证不在同一条死路上重复
- 原则 10:热经验发现触发条件必须量化——hitCount ≥ 3 且 stdDev < 0.15,拒绝主观判断
SPC-CTX 作为参考实现:附录 A 提供完整的 SPC-CTX 架构、参数和版本历史。
第六章:竞争格局与护城河
6.1 现有方案的共同盲点
| 系统 | 核心关注点 | CDA 差异化 |
|---|---|---|
| MemGPT | 层级存储(OS 虚拟内存类比) | 无 Phase-aware,无方向对齐 |
| Zep | 情景记忆 + 知识图谱 | 关注「存什么」(实体关系),而非「何时检索」 |
| LangChain Memory | 对话缓冲 + 摘要 | 无语义方向对齐,无 Phase 区分 |
| RAG | 文本相似度检索 | 检索方向 ≠ LLM 注意力方向 |
| Claude Context Editing | 自动上下文编辑 | 商业实现,非开源 |
共同盲点:所有现有系统回答的都是「上下文太多怎么办」的问题,但没有系统性地回答「在什么时机、朝什么方向、检索什么信息」。
6.2 CDA 范式的护城河分析
算法层:CDA 没有独有算法。所有核心算法(向量检索、层级记忆、语义压缩)都能在学术文献中找到。
组合层:CDA 的护城河在于 Phase × QTS × SCG × 三层内存的组合。LangChain/LlamaIndex 的 Phase 概念是粗粒度的(只有前/后),而 CDA 的 Phase 是语义级的(5 个 Phase 各有不同的检索策略)。这种粒度差异需要大量实验才能发现。
工程艺术层:CDA 的护城河在于「不该做什么」的积累知识。0% self_tag 响应率、compact 结果没被读取、QTS 参数没有实验验证——这些「不该做」是从真实失败中积累的,不是设计出来的。真正的护城河不是算法公式,而是**「如何不把协议玩崩」的调参经验**。
产品化层:协议与设计文档保持开放(CC BY-ND 4.0),但工业级实现(调参策略、图压缩细节、Dead-End Registry 的匹配阈值、多租户部署经验)构成闭源或企业版的价值。免费版提供本地可用接口,企业版提供监控 dashboard、漂移告警和多租户支持。
范式层:CDA 作为「上下文管理范式框架的建立者」的身份,是最持久也最脆弱的护城河。持久是因为范式建立者的身份无法复制;脆弱是因为范式本身可以被学习。
6.3 SPC-CTX 的定位
SPC-CTX(产品化名称为 Direction-Preserving Context Engine)是 CDA 范式的参考实现,而非 CDA 范式本身。
这意味着:
- SPC-CTX / Direction-Preserving Context Engine 会过时(随着硬件/模型/场景的演进)
- 但 CDA 范式作为理论框架可以指导其他实现
这就是为什么《CDA:超长连续任务上下文管理范式》比《SPC-CTX 技术文档》更有战略价值。
本书建立的是范式权威,而非产品文档。
本章小结
本章分析了 CDA 范式在竞争格局中的定位和护城河来源。
核心发现:所有现有系统(MemGPT / Zep / LangChain / LlamaIndex)回答的是「存什么」的问题——它们的差异化在于存储什么内容。CDA 回答的是「何时检索 + 朝什么方向检索」——这是根本性的范式差异。
SPC-CTX 的定位:不与现有框架竞争,而是开辟新的技术位置——「Context Engineering」——RAG 和 Memory 之外的第三条路。
第七章:技术债与未来方向
7.1 当前技术债
| 问题 | 影响 | 优先级 |
|---|---|---|
| Embedding API 依赖 | Embedding 质量影响整体效果 | 🟡 P1 |
| Compact 算法无 benchmark | 压缩质量无法量化评估 | 🟡 P1 |
| 指标体系与 benchmark | Alignment Stability / Dead-End Repetition Rate / ECD 的可复现 benchmark 尚不完整 | 🔴 P0 |
7.2 开放研究方向
方向 1:CDA 与模型原生注意力机制的联合优化
当前 CDA 在模型外部过滤上下文。如果能将 CDA 的方向信号传递到模型的注意力层,可能实现更精确的上下文利用。
方向 2:多 Agent 场景下的 CDA 扩展
多 Agent 协作中,每个 Agent 有自己的注意力方向。如何在 Agent 间共享上下文同时保持各自的语义方向独立性,是一个开放问题。
方向 3:CDA 的可量化评估指标
当前 CDA 的效果主要靠下游任务准确率衡量,缺乏独立的行业通用指标。本书已提出三类核心指标(Alignment Stability、Dead-End Repetition Rate、Effective Context Density),下一步需要建立可复现的 benchmark 和公开 leaderboard。
结语
CDA 不是一个功能,而是一个视角转变。
从「如何在有限窗口内放入更多信息」,到**「在只保留 10% 历史信息的前提下,如何让 Agent 的方向不跑偏、死路不走第二次」**。
前者是存储问题;后者是方向问题。
存储问题的解法是不断扩展容量(但需求永远跑在增长前面)。方向问题的解法是精准对齐与负向过滤(容量压缩,稳定性提升)。
CDA 选择后者——不是因为容量不重要,而是因为方向比容量更稀缺。真正有价值的不是「记住了多少」,而是「记住了哪些路已经证明是错的」。
本文档基于 Wilson/Blitz 的真实工程实践、SPC-CTX 开发经验、以及真实 session 运行数据(2026-04 密集期)撰写。
附录 A:SPC-CTX 参考实现
A.1 架构概览
用户输入
↓
[Phase 判定] → inferPhase(rawIntent, recentTools)
↓
[方向计算] → deltaDirection(prev, curr) → DirectionVector
↓
[组装阶段]
├─ basicAssemble (无 snapshot)
└─ fullAssemble (有 snapshot) → QTS scoring → keep/compress/dropout
↓
[压缩阶段] → SCG 语义压缩 → [Compressed] 标记
↓
[对齐评估] → computeAlignment(direction, scores)
↓
[热经验发现] → discoverHotExperiences (hitCount ≥ 3, stdDev < 0.15)
↓
LLM ContextA.2 核心参数参考
DELTA_THRESHOLD = 0.05 // 方向转移检测阈值
KEEP_THRESHOLD = 0.75 // keep/compress 边界
COMPRESS_THRESHOLD = 0.25 // compress/dropout 边界
HYSTERESIS_MARGIN = 0.10 // 滞后门边距
CAUSAL_CHAIN_N = 3 // 连续 dropout 触发强制 compress
HOT_EXPERIENCE_HITCOUNT = 3 // 热经验最小命中次数
HOT_EXPERIENCE_STDDEV = 0.15 // 热经验最大标准差A.3 SPC-CTX 版本历史
| 版本 | 关键变更 |
|---|---|
| v0.10.x | 引入 compact sidecar 模式 |
| v0.13.0 | 三层内存架构建立 |
| v0.15.x | QTS 形式化引入 |
| v0.16.0 | P0 Bug 修复:assemble 终于读取 context_items,compact 不再白跑 |
A.4 当前运行状态(2026-04-13)
SPC-CTX version: v0.16.0
messages table: 1287 items, 611K tokens
context_items: 90 items (compact 精选集)
QTS scoring: active (compact 子集, 90 items)
last compact: 2026-04-13 16:04 CSTA.5 最小对外 API(v1.1.0+)
// 写入一轮对话与工具轨迹
appendTurn({ messages: Message[], tools: ToolCall[], phase: Phase })
// 组装本轮需要喂给模型的最小上下文
assembleContext({
query: CurrentIntent,
max_tokens: number
}) => AssembledContext
// 触发压缩(可由外部按需调用)
compact({ strategy?: 'auto' | 'aggressive' })
// 查询语义方向状态(调试、监控)
getDirectionState() => {
global_intent: IntentVector,
drift_score: number,
dead_end_matches: DeadEndMatch[]
}
// 显式注册一条死路(负向经验)
registerDeadEnd({ session_id: string, trace: object, reason: string })
// 列出已知死路(调试、UI 展示)
listDeadEnds({ session_id: string, top_k?: number }) => DeadEndItem[]附录 B:术语表
| 术语 | 符号 | 定义 |
|---|---|---|
| 语义方向 | D | LLM 注意力当前指向的语义空间区域 |
| 语义梯度 | G = dD/dt | 语义方向的变化率 |
| 方向对齐度 | ⟨D_target, D⟩ | 目标方向与当前方向的余弦相似度 |
| QTS 分数 | QTS(m, D) | 消息 m 相对于方向 D 的相关度分数 |
| Phase | p ∈ {A, I, T, C, B} | Agent 行为阶段 (assemble/ingest/afterTurn/compact/bootstrap) |
| 滞后门 | H | 防止分数震荡导致内容闪烁的机制 |
| 因果链保护 | N | 连续 N 次 dropout 后强制 compress;N=3 |
| 死路记录 | miss | 已被证伪的论点/证据链方向 |
| 过滤梯度 | decay | miss 历史导致的后续权重衰减 |
| 热经验 | hot | 同一方向 hitCount ≥ 3 且 stdDev < 0.15 的稳定成功模式 |
| 冷经验 | cold | 尚未达到热经验标准的经验 |
| SCG | Semantic Context Graph | 保留语义拓扑结构的压缩算法 |
| SPC-CTX | Semantic Phase Context | CDA 范式的参考实现 |
| CDA | Context Direction Alignment | CDA 范式的核心 |
| Direction-Preserving Context Engine | — | CDA 范式的对外产品名称 |
| Dead-End Registry | — | 负向经验库,记录被证伪的推理链/工具调用组合 |
| Alignment Stability | — | 方向稳定性:当前方向与全局意图的语义相似度随轮数的变化 |
| Dead-End Repetition Rate | — | 死路重复率:已证伪策略在后续被重复尝试的比例 |
| Effective Context Density (ECD) | — | 有效上下文密度:成功用于推理的历史信息占总 token 的比例 |