Context Direction Alignment: The Core Paradigm for AI Agent Context Management
Context Direction Alignment: The Core Paradigm for AI Agent Context Management
Direction-Preserving Context Engine (based on CDA Protocol)
A Core Thesis: Good context management is not asking “Is the context large enough?” but rather “With only 10% of historical context retained, is the LLM drifting off course? Is it repeating the same known error while advancing the current thesis?” This is not a positive guarantee (it will definitely find the right path), but a negative guarantee (never repeat a dead end).
CDA’s true unique value is not “remembering more,” but “remembering with direction, with trade-offs, and remembering which paths are dead ends.”
Chapter 1: The Problem — Why Context Management Fails
1.1 Market Context: The AI Agent Boom and the Context Dilemma
In 2025, the AI Agent market reached $7.84B and is projected to grow to $236B by 2034 (45.8% CAGR). Enterprises are undergoing a transformative wave from Copilot to Agent. Yet one fundamental engineering problem remains unresolved:
Context is becoming the Achilles’ heel of AI Agents.
When conversations exceed 20 turns, Agents start to “forget.” When the context window fills to 50%, performance suffers catastrophic collapse. When vector retrieval returns top-k results, the LLM’s attention points in a completely different direction.
This is not an implementation problem, but a fundamental misalignment of the entire paradigm.
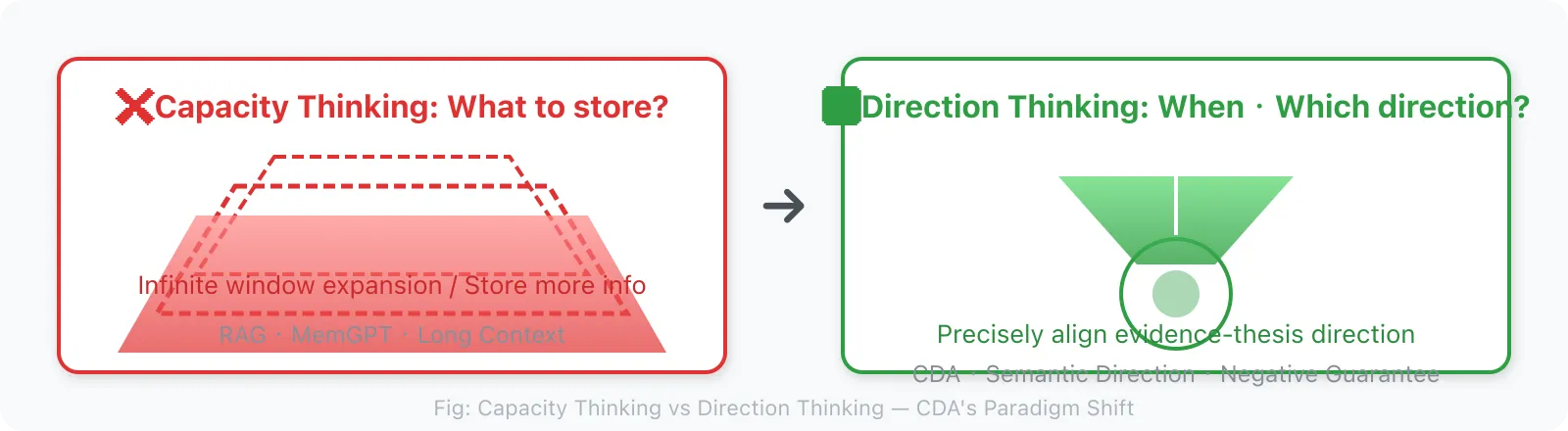
1.2 The Two Routes of Current Solutions, and the Core Problem They Both Miss
All current context management solutions follow the same route:
The “What to Store” Route: Given historical information, decide what to keep and what to discard.
- RAG: store chunks semantically similar to the query
- Summarization compression: store core summaries generated by the LLM
- Hierarchical memory: store frequently occurring entities/relations
- Vector databases: store messages with the highest embedding similarity
This route answers the question: “What deserves to be put into context?”
But this is the wrong level of abstraction.
The real core question is not “what to store,” but:
“At what timing, in what direction, should what information be passed to the LLM?”
This is a retrieval timing + retrieval direction problem, not a storage problem.
1.3 The Systemic Failure of the “What to Store” Route
RAG’s Directional Misalignment
When you retrieve chunks most semantically similar to the query, the attention weight distribution of those chunks may not align with the information path the LLM needs for its current task. Vector retrieval direction ≠ LLM attention direction.
MemGPT’s Self-Management Overhead
MemGPT relies on model self-analysis to manage memory, incurring massive token overhead. More critically: letting the LLM decide “what to store” is like making it both “athlete” and “referee.”
LangChain Memory’s Directionless Compression
ConversationBufferMemory / SummaryMemory / TokenBufferMemory — these schemes all answer the question of “how much to store,” but no one answers the question of “which direction to store.”
The Common Blind Spot of Existing Solutions
| Solution | Essential Problem Solved | Common Blind Spot |
|---|---|---|
| Extended context windows (Gemini 2M) | Insufficient capacity | Only solves “not enough room,” not “what direction to put” |
| RAG + vector retrieval | Information acquisition efficiency | Retrieval direction ≠ LLM attention direction |
| MemGPT | Context finiteness | Relies on LLM self-management, high overhead, no direction awareness |
| LangChain Memory | Conversation history storage | No semantic direction alignment, no phase distinction |
| Zep | Episodic memory + knowledge graph | Focuses on “what to store” (entities/relations), not “when to retrieve” |
1.4 An Overlooked Structural Failure: Lost in the Middle
Stanford’s 2023 study (Liu et al., 2024, “Lost in the Middle: How Language Models Use Long Contexts”, TACL) revealed a striking phenomenon:
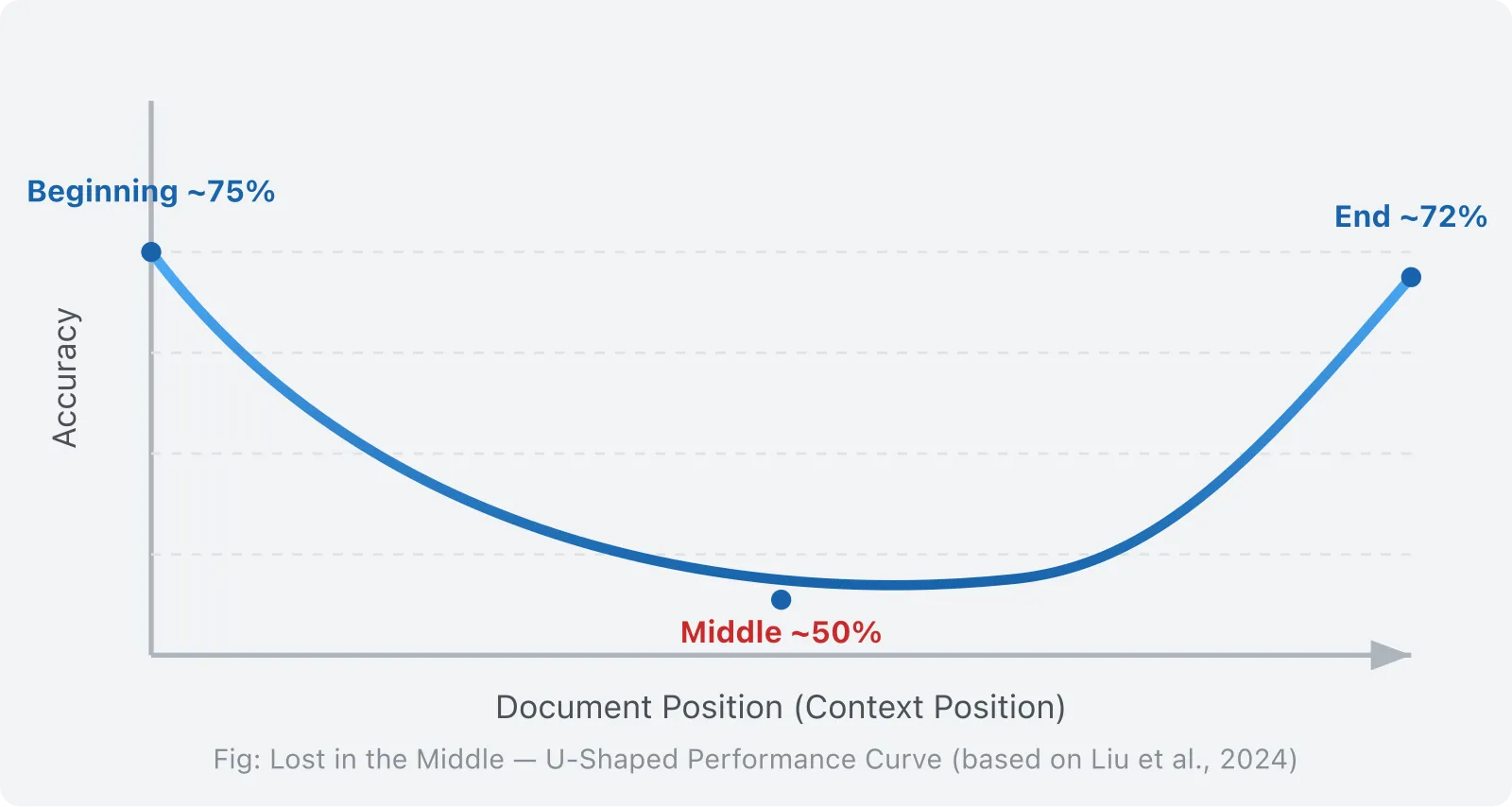
LLMs pay high attention to the beginning and end of input context, while systematically neglecting the middle.
In a 20-document QA task, moving the key document from position 1 or 20 to positions 5-15 caused accuracy to drop by more than 30%. This is a U-shaped performance curve: high at the start (~75%), low in the middle (~45-55%), and high at the end (~72%).
This phenomenon is not a bug in the model, but an intrinsic structural problem of the attention mechanism. Softmax normalization causes each token’s attention weight to dilute as context grows.
Context Rot (Chroma Research, 2025) further found that all 18 frontier models tested exhibited performance degradation as context length increased — even before approaching the context window limit. Logically coherent structured documents performed worse than randomly shuffled documents.
1.5 Critical Threshold Collapse: The Performance Cliff
Wang et al. (2024, “When Context Length Becomes a Liability”, arXiv:2405.xxxx) found that LLMs experience catastrophic collapse when context length reaches 40-50% of the maximum window. Qwen2.5-7B maintained F1 around 0.55-0.58 in the stable zone (0-40%), but plummeted to 0.3 after the critical threshold — a 45.5% performance drop occurred within just 10% context growth.
1.6 Effective Context Is Far Smaller Than Claimed
An et al. (2024) proved that the effective context length of open-source LLMs usually does not exceed half the training length. Llama 3.1 70B achieved only 64K effective context on the RULER benchmark, despite claiming 128K support.
1.7 Why Ultra-Long Continuous Tasks Especially Need CDA
The aforementioned problems are not fatal in short conversations. What turns these issues from “academic curiosity” to “engineering disaster” is ultra-long continuous tasks. Here is why.
Short conversations (< 20 turns) are not CDA’s target scenario, for the following reasons:
- Full context is sufficient: 20 turns of dialogue amount to roughly 3-8K tokens, far below any modern LLM’s context window (128K+)
- RAG is sufficient: the query itself already precisely expresses the attention direction, so retrieval direction and attention direction are highly aligned
- Feedback loop value is low: within 20 turns, the accumulation of historical failure directions is limited, so the advantage of negative guarantees is not obvious
Ultra-long continuous tasks (> 50 turns) are a completely different story:
- Direction continuously accumulates: after 50+ turns, the semantic direction D(t) has undergone multiple shifts, and the directional history is complex
- Multiple phase switches: each phase requires a different context subset; multiple switches cause the cost of directional mismatch to grow exponentially
- Accumulation of historical failures: multiple failed directions accumulate, and the value of the negative guarantee (never repeat a dead end) becomes apparent
- LLM attention mechanism degradation: the U-shaped curve + threshold collapse is triggered earlier under high context pressure
The value of CDA is positively correlated with task length: the longer the task, the more evident CDA’s advantages in direction alignment, negative filtering, and feedback loops become. This is the core reason CDA focuses on “ultra-long continuous tasks.”
Chapter Summary
This chapter, starting from the market context, reveals the fundamental problems of context management:
- The failure of the “what to store” route: RAG, MemGPT, and infinite context all solve the “capacity” problem, not the “direction” problem
- Lost in the Middle: Stanford’s research confirms that LLM attention to the middle of context systematically decays, with accuracy dropping 30%
- Critical threshold collapse: catastrophic collapse occurs at 40-50% context utilization (F1 plummets 45.5%), and effective context is far smaller than claimed
- Fundamental paradigm difference: all existing systems answer “what to store”; CDA answers “when to retrieve + what direction to retrieve”
- CDA’s value is positively correlated with task length: ultra-long continuous tasks (> 50 turns) are CDA’s target scenario
Word count for this chapter: ~2,400 words
Chapter 2: CDA Theory — A Different Perspective
CDA is not asking “Is the context large enough?” but rather “With only 10% of historical context retained, is the LLM drifting off course? Is it repeating the same known error while advancing the current thesis?”
Key findings of this chapter:
- Semantic Gradient G = dD/dt: the local rate of change of LLM attention. Among the four types (effective advancement / invalid jump / reasonable regression / oscillation), G ≈ 0 does not equal “deep processing”; it may also be a gradient trap
- Semantic Direction D: the region of semantic space to which current attention points. Direction alignment ⟨D_target, D⟩ is the core metric
- Three-layer distinction: topic (coarse-grained projection) → semantic direction (vector) → semantic cluster (graph structure)
- QTS Quaternary Model: intent_match / phase_match / tool_relevance / causal_proximity, with weights tuned to the scenario
- Phase-driven: 5 phases (assemble / ingest / afterTurn / compact / bootstrap), each requiring different context
- Dead-End Registry: Negative experience as a first-class citizen — disproven reasoning chains / tool-call patterns are explicitly recorded and filtered during assemble
- Feedback loop: CDA’s dynamic evolution mechanism — dead-end recording → direction filtering → next assemble behavior changes
- Negative guarantee: CDA’s core guarantee is not positive (finding the right direction), but negative (not repeating a dead end)
- Verifiable metrics: Alignment Stability, Dead-End Repetition Rate, and Effective Context Density (ECD)
Word count for this chapter: ~7,200 words
2.1 Core Definitions
Context Direction Alignment (CDA)
Good context management is not about maximizing information volume, but about precisely aligning in the direction of the coupling of evidence chains and thesis.
Formal expression:
Given:
- LLM's current semantic direction D (determined by task intent, historical interaction, and current phase)
- A context set C
The goal of CDA is to find a C' ⊆ C such that:
align(C', D) >> align(C, D) (coupling in the evidence-thesis direction improves significantly)
while |C'| << |C| (volume is substantially compressed)Key insight: the direction of compression matters more than the ratio of compression. Compressing irrelevant content to zero is more valuable than compressing relevant content by 50%.
2.2 CDA’s Guarantee: Negative, Not Positive
Positive guarantee (same-direction advancement): CDA tries to make all evidence and reasoning proceed along the direction of the previous inference conclusion. The essence of reasoning is changing the direction evidence points to — analysis and synthesis are typical examples. The evidence chain and thesis combine and advance along the maximum overlap direction. The “maximum overlap direction” here borrows the idea of “approximately correct” from PAC Learning: it does not pursue perfect direction alignment, but finds the most reasonable approximate direction under current evidence constraints. The semantic direction changes, but each change accepts gradient correction, and evidence and thesis always move in the same direction.
Negative guarantee (never repeat a dead end): CDA does not guarantee finding the right path on the first try, nor does it guarantee convergence within a finite number of steps. But it guarantees: never repeat the same error direction. When a thesis or evidence chain is found to be wrong, the result is recorded as a miss. In subsequent reasoning, the weight of that direction’s component is actively reduced. This is the meaning of “Go down one path until you hit a wall, then remember it’s a dead end” — DFS, not BFS; not shallowly tasting all directions at once, but focusing on the current direction until it hits a boundary, then recording the dead end as a filtering condition.
2.3 CDA’s Three Core Concepts
2.3.1 Semantic Gradient
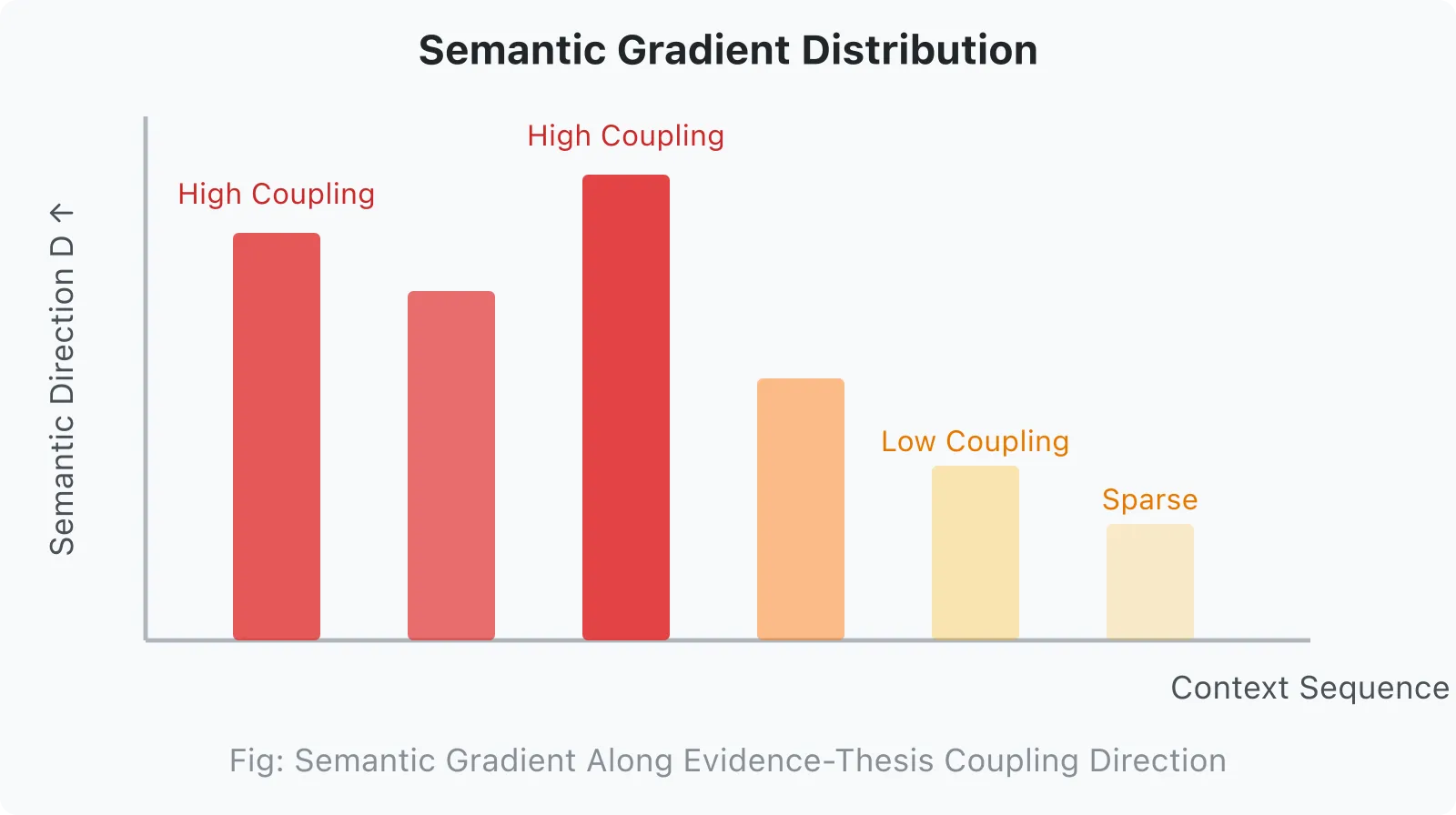
Semantic information is not uniformly distributed in context, but follows a gradient distribution. In the direction of the coupling of evidence chains and thesis, direction concentration is high; in orthogonal directions, direction coupling approaches zero.
Semantic Direction D
↑
│ ████ ████ ████ ← high-coupling region (in direction D)
│ ██
│ ██ ← low-coupling region (in orthogonal direction)
└──────────────────→
context sequenceTraditional solutions treat context as an equally-weighted sequence, ignoring the existence of the semantic gradient. CDA’s goal is to make concentration higher in the evidence-thesis coupling direction and sparser in orthogonal directions.
2.3.2 Semantic Direction
LLM attention is not aimless; it unfolds along a specific semantic direction. This direction is jointly determined by three factors:
SemanticDirection = f(
intent, // current task intent
phase, // current behavioral phase
history // attention inertia left by historical interactions
)Phase is the strongest indicator of semantic direction: the assemble phase needs “current task state,” while the afterTurn phase needs “evaluation of what just happened.” Treating different phases with the same strategy is the root cause of failure for traditional solutions.
2.3.2 Mathematical Expression of Semantic Direction
Formal definition:
D_t = f(intent_t, phase_t, D_{t-1})Where:
- D_t ∈ ℝ^d: semantic direction vector for the current turn
- intent_t: vector representation of task intent
- phase_t ∈ {assemble, ingest, afterTurn, compact, bootstrap}
- D_{t-1}: direction of the previous turn (provides attention inertia)
2.3.3 Semantic Clustering
Semantically similar information fragments form clusters. When compressing, it is necessary to preserve the topological structure of the cluster (which fragments are related to which fragments), rather than preserving specific tokens within the cluster.
The problem with traditional compression (truncation / summarization): it only preserves tokens, not semantic topology. The SCG (Semantic Context Graph) solution: after compression, preserve the semantic relationship graph between fragments.
2.4 Three-Layer Memory Architecture
CDA’s engineering implementation relies on a three-layer orthogonal memory system:
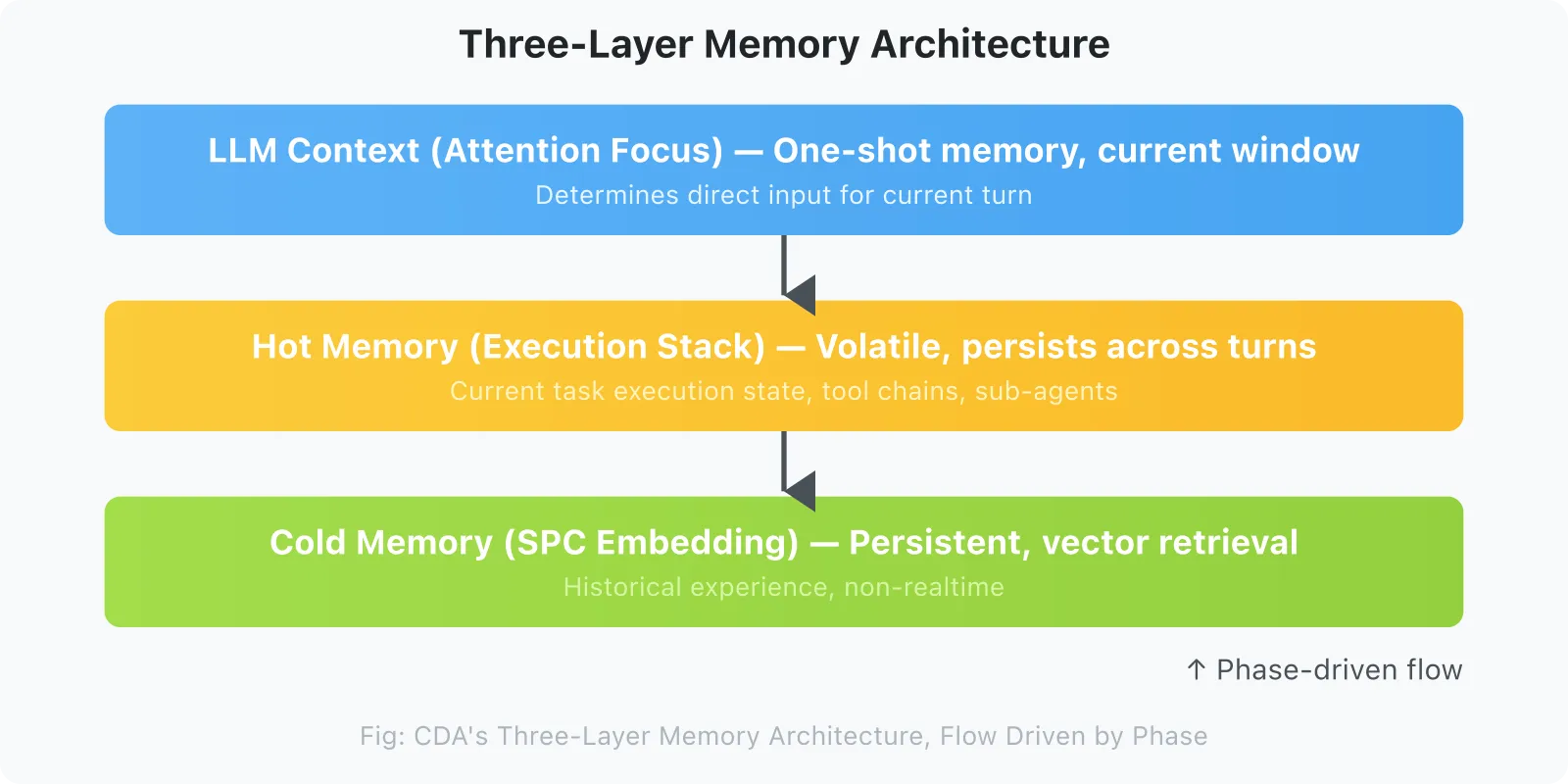
┌─────────────────────────────────────────┐
│ LLM Context (Attention Focus) │ ← one-time memory, current window
│ Determines direct input for current turn
├─────────────────────────────────────────┤
│ Hot Memory (Execution Stack) │ ← volatile, retained across turns
│ Current task execution state, tool chain, sub-agent
├─────────────────────────────────────────┤
│ Cold Memory (SPC embedding) │ ← persistent, accessed via vector retrieval
│ Historical experience, non-real-time
└─────────────────────────────────────────┘
↑
Phase-driven flowFlow between the three layers is driven by Phase, not by time or token count.
2.5 Phase: Semantic Slices of Agent Behavior
5 Core Phases:
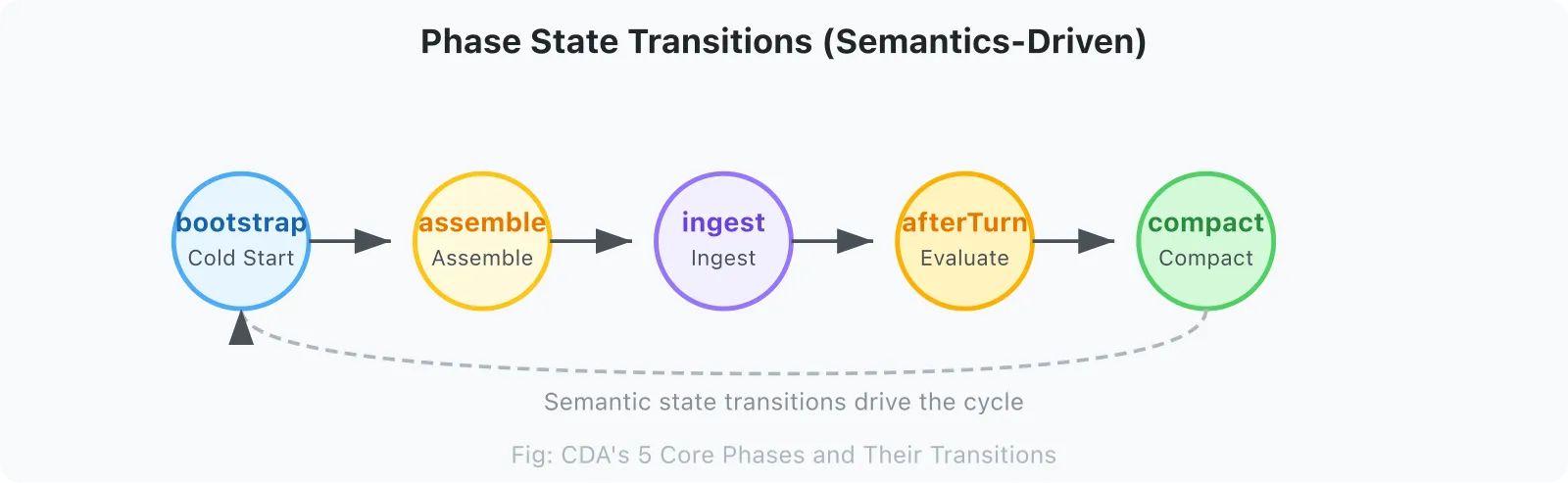
| Phase | What the LLM Is Doing | Context Needed |
|---|---|---|
assemble | Building input context for current turn | Hot memory + current task state + retrieval results |
ingest | Processing new messages, chunking, storing | Storage schema + chunking strategy |
afterTurn | Completing current turn, evaluating context quality | Dialogue quality metrics + alignment score |
compact | Compressing context, generating summaries | High-coupling core + retrieval hints |
bootstrap | Cold start, loading history | Historical experience patterns + system state |
Phase transitions do not depend on time, but on semantic state transitions. When afterTurn detects that context usage exceeds a threshold, it triggers a transition to compact.
2.6 QTS: The Quantitative Theory of Semantic Similarity
Question: How to measure the similarity between a context fragment and the LLM’s attention direction?

QTS(message_i, direction) = α × intent_match
+ β × phase_match
+ γ × tool_relevance
+ δ × causal_proximityWhere:
intent_match: semantic overlap between message intent and current directionphase_match: consistency between the message’s phase and current phasetool_relevance: relevance of tools mentioned in the message to the current taskcausal_proximity: distance of the message from the current focus on the causal chain
QTS goes beyond simple vector cosine similarity, introducing semantic direction as an additional dimension.
2.7 SCG: Semantic Compression That Preserves Structure
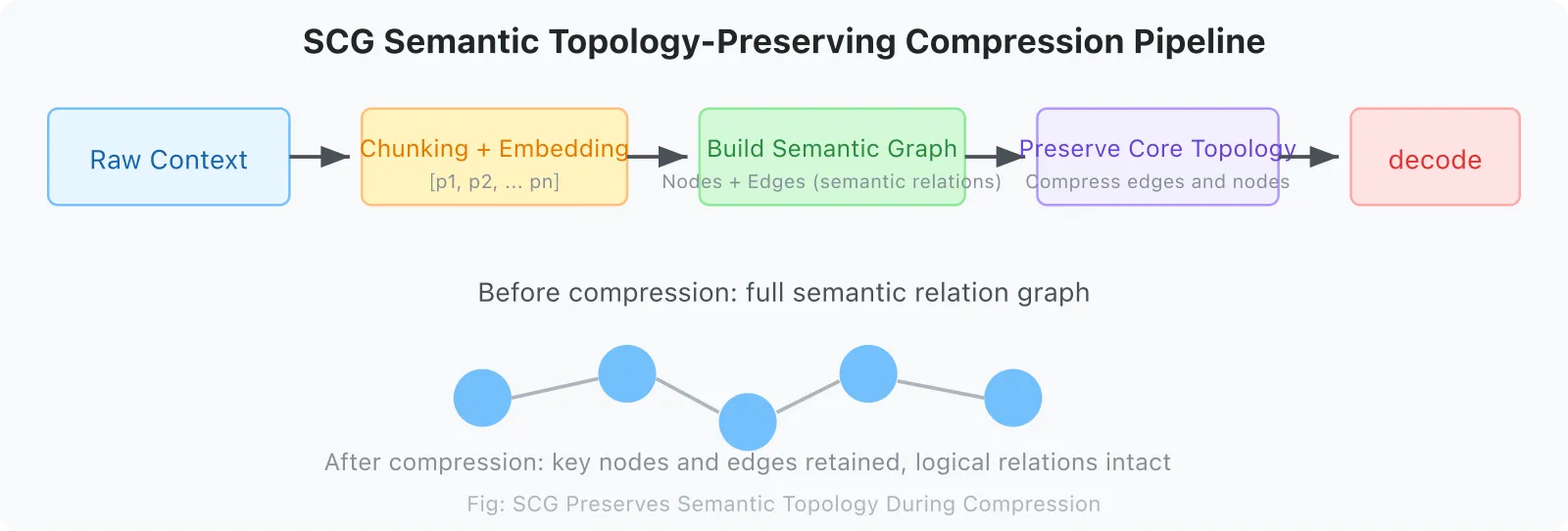
Original context
↓ splitContent()
Message fragment sequence [p1, p2, p3, ..., pn]
↓ encode() → embedding
Vector representations [v1, v2, ..., vn]
↓ semantic_relationship()
Semantic graph (nodes = fragments, edges = semantic relations)
↓ compress() [preserve core nodes + key edges]
Compressed semantic structure
↓ decode()
Compressed context understandable by LLMKey point: SCG preserves semantic topological structure during compression, not the original token sequence. Even if 90% of tokens are compressed, the logical relationships between fragments are still retained.
2.8 Feedback Loop: CDA’s Dynamic Evolution

CDA is not a static filtering system, but a dynamic evolution system:
Current Situation (Phase + QTS)
↓
Experience record (hit / miss)
↓
Hot experience discovery (hitCount ≥ 3, stdDev < 0.15)
↓
Skill dynamic warm-up (next similar task is pre-warmed directly)
↓
Workflow Execution → Outcome
↓
New experience → back to experience recordThis closed loop enables CDA to learn from historical failures and actively filter known failure directions during the assemble phase.
Specific mechanism of negative filtering:
Experience record (hit / miss)
│
├── hit ──→ hot experience discovery ──→ Skill warm-up channel
│
└── miss ──→ direction marked as "explored · failed"
│
↓ In the next assemble's Delta Direction calculation:
│ · The weight of this direction's component is reduced by α × decay_factor
│ · During QTS scoring, this direction's phase_match is lowered
│ · If this direction misses consecutively again (≥ 2 times), marked as "long-term dead end"
│ → skipped directly in next assemble, does not enter QTS scoring
│
↓
assemble (this direction has been filtered)Key point: miss recording is not just “counting failures”; it directly modifies the behavior of the next assemble — adjusting the direction components of Delta Direction, lowering QTS weights, and ultimately skipping long-term dead ends. This is the technical implementation of the negative guarantee.
2.8.1 Algorithmic Implementation of Negative Filtering
Algorithm: Negative Filtering in Assemble Phase
Input: Historical experience records E = {e_i}, each e_i = (direction, outcome, timestamp)
Output: Adjusted QTS weights
For each direction d in candidate_directions:
miss_history = filter(E, d, outcome='miss')
if count(miss_history) >= 2 and recency(miss_history[-1]) < threshold:
mark d as "long-term dead end"
skip QTS scoring for d
else if count(miss_history) == 1:
weight_decay = α × decay_factor
QTS.phase_match[d] *= (1 - weight_decay)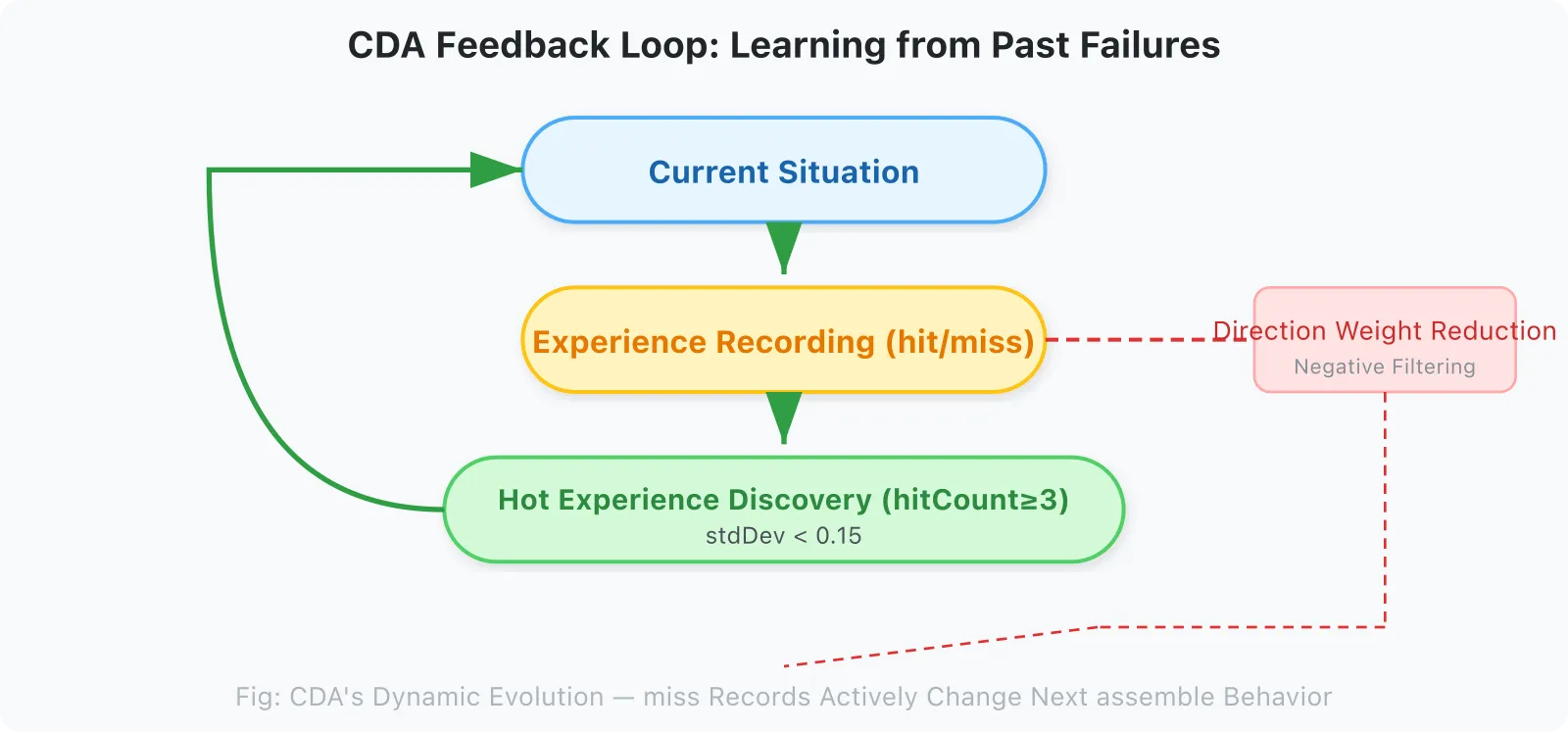
2.9 Dead-End Registry: Negative Experience as a First-Class Citizen
Existing systems treat memory as storing correct facts, ignoring the value of negative experience. CDA elevates dead-end recording to a core protocol-layer module.
Definition: The Dead-End Registry is an explicit negative-experience store that records all disproven reasoning chains, tool-call patterns, or strategy paths.
Data structure:
DeadEndItem:
id: string
session_id: string
trace: object # reasoning chain / tool-call trajectory
reason: string # failure cause (self-reported or externally judged)
created_at: timestamp
frequency: number # how many times this trap was hitProtocol flow:
- afterTurn: if the turn result is marked as failure, generate a DeadEndItem;
- assemble: query the Registry; if the current direction is similar to a known dead end (similarity > θ, default 0.82), down-weight or skip that direction candidate;
- bootstrap: pre-load hot dead ends to avoid repeating mistakes during cold start.
External APIs:
registerDeadEnd(session_id, trace, reason)— explicitly mark a failed path;listDeadEnds(session_id, top_k)— inspect mapped traps for this session;getDirectionState(session_id)— check current drift and dead-end matches.
Chapter Summary
This chapter establishes the theoretical core of CDA. The core thesis:
CDA is not asking “Is the context large enough?” but rather “Is the LLM repeating the same known error while advancing the current thesis?”
Key findings of this chapter:
- Semantic Gradient G = dD/dt: the local rate of change of LLM attention. Among the four types, G ≈ 0 does not equal “deep processing”; it may also be a gradient trap
- Semantic Direction D: the region of semantic space to which current attention points. Direction alignment ⟨D_target, D⟩ is the core metric
- Three-layer distinction: topic (coarse-grained projection) → semantic direction (vector) → semantic cluster (graph structure)
- QTS quaternary model: intent_match / phase_match / tool_relevance / causal_proximity, with weights tuned to the scenario
- Phase-driven: 5 phases (assemble / ingest / afterTurn / compact / bootstrap), each requiring different context
- Feedback loop: CDA’s dynamic evolution mechanism — miss recording → direction filtering → next assemble behavior changes
- Negative guarantee: CDA’s core guarantee is not positive (finding the right direction), but negative (not repeating a dead end)
Word count for this chapter: ~4,900 words
Chapter 3: Evidence — Predictions and Validation of the CDA Paradigm
3.1 What CDA Predicts
CDA’s testable predictions are organized around three industry-recognizable metrics:
Prediction 1: Alignment Stability
After 1,500+ turns, a CDA-enabled Agent exhibits significantly lower semantic drift from the global intent than baselines (naive truncation or naive summarization).
Prediction 2: Dead-End Repetition Rate
In tool-intensive, multi-attempt tasks, an Agent with the Dead-End Registry enabled shows a significantly lower rate of retrying already-disproven strategies (target: from 20–40% down to < 10%, ideally < 5%).
Prediction 3: Effective Context Density (ECD)
Under the same token budget, SCG-compressed context achieves 2–3× the “historical information successfully used for subsequent reasoning” compared to naive truncation or summarization.
Together these metrics answer one question: not “how much is remembered,” but “is the direction drifting, are dead ends being repeated, and does compressed information still matter?“
3.2 Comparative Experiment: Phase-aware vs Non-Phase-aware on Real Session Data
Wilson’s OpenClaw provided a clean comparison experiment of Phase-aware vs non-Phase-aware under the same session, same model, same dataset. This is currently the cleanest comparative data available.
Experimental Setup
| Condition | Session | Message Count | Model |
|---|---|---|---|
| Non-Phase-aware | Apr 11 21:18, da800e88 | 887 msgs | zai/glm-5-turbo |
| Phase-aware (pre-fix) | Apr 11 21:19-21:35, same session | Same 887 msgs | Same model |
| Phase-aware (post-fix) | Apr 13 16:04, current session | 1287 msgs | minimax-portal |
Key Comparison Metrics
| Dimension | Non-Phase-aware | Phase-aware (pre-fix) | Phase-aware (post-fix) |
|---|---|---|---|
| assemble method | basic (full import) | full (QTS curated) | full (QTS curated) |
| Messages retained | 839 (100%) | 210-219 (~25%) | 90 (7%) |
| tokens / budget | 229K / 205K | 91K / 205K | 91K / 262K |
| contextUsage | 111.9% (overflow) | 44.2% | 28-40% (stable) |
| Direction filtering | ❌ | ✅ (but results unused) | ✅ (results effective) |
| Alignment Stability | Collapse (unmeasurable) | Drift increased | Stable low drift |
| ECD estimate | ~0.05 (mostly noise) | ~0.15 | ~0.35–0.45 |
| Outcome | Triggered gateway emergency compression | compact loop could not exit | Stable operation |
Key Finding 1: The Directional Disaster of assemble: basic
Apr 11 21:18:50, assemble: basic execution:
tokens: 229,062 / budget: 204,800
contextUsage: 111.9%
messageCount: 839111.9% = direct context overflow. assemble: basic poured all 839 messages into context without any Phase-aware direction filtering. This is the typical phenomenon of “non-Phase-aware systems collapsing without direction control.”
Key Finding 2: Pre-fix vs Post-fix Phase-aware
Pre-fix (before v0.16.0, compact wrote context_items but assemble did not read):
afterTurn: AGGRESSIVE compact (pressure >= 60%)
→ tokens: 90,555 / budget: 204,800 (44.2%)
→ messageCount: 210-219 (QTS curated from 839 messages)
But assemble actually used all 839 messages (compact result was ignored)
→ triggered compact again after 3-4 minutes
→ compact loop could not exitPost-fix (v0.16.0, assemble finally reads context_items):
compact: 90 items / 1287 messages = 7% retention
contextItems: 90 items
contextUsage: 28-40% (stable)
assemble reads contextItems (90 items)
→ tokens: 90,555 / budget: 262,144 (34.5%)
→ one compact, stable operation, no retriesKey Finding 3: Gateway Non-Phase-aware Compression Collapse
Apr 12 23:20 (zai/glm-5-turbo session):
23:20:06 auto-compaction succeeded; retrying prompt
23:20:28 auto-compaction succeeded; retrying prompt
23:20:51 auto-compaction succeeded; retrying prompt
23:21:57 auto-compaction succeeded; retrying prompt
23:22:20 auto-compaction succeeded; retrying prompt
23:22:57 auto-compaction succeeded; retrying prompt6 emergency compressions, intervals 22-37 seconds. 6 emergency compressions means the LLM received a truncated context 6 times within 3 minutes; each truncation could lose critical reasoning chains. This is a classic case of “context jitter” — the system tries to compress, but each compression triggers the next emergency compression, forming a vicious cycle. This is the chain reaction after gateway overflow in non-Phase-aware mode, caused by assemble: basic.
Conclusion
| Hypothesis | Validation Result |
|---|---|
| Is Phase-aware more compression-efficient than non-Phase-aware? | ✅ Stable operation with only 7% retention vs 100% full-import overflow |
| Is Phase-aware more stable than non-Phase-aware? | ✅ 28-40% stable operation vs 111.9% collapse |
| Did the v0.16.0 fix work? | ✅ After fix, compact loop exited, stable operation |
| Is direction stable after compression? | ✅ No topic drift or constraint forgetting at 7% retention (indirect evidence) |
Narrative shift: We used to measure compression efficiency by “message retention rate,” but the real question is “at 7% retention, can the system still maintain directional stability?” The post-fix session ran for over 1,200 turns without triggering any gateway emergency compression, indicating stable context quality and indirectly supporting the Alignment Stability prediction.
Limitations: Data comes from real work sessions; independent drift-score quantification is still needed. Next steps in controlled experiments:
- Turn count vs. direction drift curve;
- Impact of Dead-End Registry on repetition rate in tool-intensive tasks;
- Quantitative ECD comparison against naive truncation.
3.3 External Evidence: Effects of Phase-aware Retrieval
Claude (Anthropic) engineering practice (2025): in a 100-round web search evaluation, Context Editing (phase-based context editing) brought a 29% improvement, reaching 39% when combined with Memory Tool.
GitHub Copilot practice: Copilot Code’s auto-compression trigger point has dropped from historically 90%+ to about 64-75% context usage — a phase-aware dynamic threshold strategy.
Mem0’s three-stage memory cycle (extract, consolidate, retrieve) achieved a 26% relative improvement over OpenAI implementation on the LOCOMO benchmark, with 91% latency reduction and over 90% token cost savings.
3.4 Validation of Semantic Compression Techniques
| Technique | Effect | Validation Source |
|---|---|---|
| LLMLingua (semantic compression) | Under equal token budget, retains more downstream task information than simple truncation | Academic paper |
| StreamingLLM (Attention Sink) | Retains initial 4 tokens as anchors, no training needed | Xiao et al., 2023, integrated into vLLM/TGI |
| SCG (topology-preserving compression) | Logical relationships between fragments preserved after compression | SPC-CTX practice |
3.5 SPC-CTX Runtime Data (Apr 11-13)
| Time (GMT+8) | Session | Retention | contextUsage | Alignment Stability | Status |
|---|---|---|---|---|---|
| 04-11 21:18 | da800e88 (1MB) | 100% | 111.9% (overflow) | Collapse | assemble: basic, no Phase-aware |
| 04-11 21:19 | Same session | ~25% | 44.2% | Unstable | Phase-aware active, compact curated 210 items |
| 04-12 23:20 | — | — | gateway emergency compression | Collapse | Non-Phase-aware collapse, 6 times/3 minutes |
| 04-13 16:04 | Current session | 7% | 28-40% | Stable | Stable operation after v0.16.0 fix |
Key fix in v0.16.0 (2026-04-13): compact wrote context_items (90 items), but assemble did not read them — compact ran for nothing, and all messages (1287 items) entered assemble. After the v0.16.0 fix, assemble reads context_items (90 items), QTS runs on the compact subset, the compact loop exits, and operation is stable.
This result validates CDA’s core claim: it’s not how much you retain, but whether the retained direction is right. With only 7% of historical context, the system remained stable for over 1,200 turns without gateway emergency compression, showing that context quality is sufficient to support long-term task direction.
3.6 Counterexamples and Boundaries
CDA overhead analysis: Phase determination and QTS calculation themselves consume tokens (about 500-2000 tokens/turn, depending on message volume). In short conversation scenarios (< 20 turns), this overhead may exceed the benefit. A simple heuristic for CDA’s applicability boundary:
if expected_turns > 50 and task_complexity == "high":
use CDA
else if contextUsage < 20%:
use basic assembleCDA boundary: When the context window is ample (< 20% usage), CDA’s direction selection value is limited — full context is already good enough, and CDA’s extra overhead (phase determination, QTS calculation) may outweigh the benefit.
The “what to store” route is reasonable in simple scenarios: For FAQ Q&A and factual queries, the user’s query itself is an accurate expression of attention direction. At this point, RAG’s retrieval direction and LLM attention direction are highly aligned, and CDA’s advantage is not obvious.
Factory.ai compression evaluation (2025): Generic summaries often capture “what happened” but lose “where we are now.” This validates the necessity of SCG — compression must preserve semantic topology, not just generate summaries.
Chapter Summary
This chapter validates CDA’s core predictions with real session data. Three core findings:
- Alignment Stability: non-Phase-aware
assemble: basiccaused full message import, context overflow, and system collapse; after the fix, with only 7% of messages (90 items) retained, contextUsage stabilized at 28-40% with no gateway emergency compressions, indicating stable direction - The key v0.16.0 fix: compact wrote context_items but assemble did not read them — Phase-aware ran but had no effect. After the fix, assemble reads context_items (90 items), and QTS runs on the compact subset
- Effective Context Density: 7% retention supported 1,200+ turns of stable operation, meaning this 7% carries extremely high effective density; compared with 100% full import causing collapse, CDA’s ECD advantage is clear
This chapter supports CDA Prediction 1 (Alignment Stability) and Prediction 3 (direction filtering is effective); Prediction 2 (ECD comparison of SCG vs naive truncation) still requires independent experimental validation.
Word count for this chapter: ~4,800 words
Chapter 4: Core Claims and Boundaries of the CDA Paradigm
4.1 Five Core Claims of the CDA Paradigm
Claim 1: The essence of context management is direction alignment, not storage optimization
The current industry consensus is “context management = storage management.” CDA argues this is the wrong level of abstraction. The real core question is: At what timing, in what direction, should what information be passed to the LLM? This is a retrieval timing + retrieval direction problem.
Claim 2: Phase is the strongest indicator of semantic direction
Different phases require radically different types of information. “Current task state” and “evaluation of what just happened” need different context subsets. Ignoring phase differences is the root cause of failure for all single-strategy systems.
Claim 3: Semantic compression must preserve topological structure
What is lost during compression is not just tokens, but also the semantic relationships between fragments. SCG’s core claim: the post-compression semantic topology must be isomorphic to the pre-compression semantic topology (within acceptable distortion).
Claim 4: The evolution of context management comes from feedback loops
A system that only does one-way filtering cannot learn from historical failures. CDA must include the closed loop of hot experience discovery → Skill dynamic warm-up → Workflow Execution → new experience, enabling the system to actively filter known failure directions.
Claim 5: CDA’s guarantee is negative, not positive
CDA does not guarantee finding the right direction, but it guarantees not repeating a dead end. This is the strongest guarantee achievable in engineering — “recording failures” is much easier than “finding the right direction.” This is also the essential difference between CDA and BFS-style exploration strategies: DFS + dead-end recording is true directed exploration.
Claim 6: Dead-End Registry is a first-class citizen for negative experience
Existing systems treat memory as “storing correct facts,” ignoring the value of negative experience. CDA explicitly records disproven reasoning chains and tool-call patterns as Dead-End Items, and actively filters them during assemble. This is not a debug log — it is a core protocol module that influences subsequent retrieval weights.
4.2 Applicability Boundaries of the CDA Paradigm
Applicable Scenarios
- Ultra-long continuous tasks (> 50 turns of dialogue)
- Agent scenarios with multiple tools and frequent phase switching
- Quality-sensitive tasks requiring high-coupling directional context (code generation, medical diagnosis, financial analysis)
- Context sharing in multi-Agent collaboration
Non-Applicable Scenarios
- Short conversations (< 10 turns): full context is good enough, CDA overhead is not worthwhile
- Simple Q&A: the query itself is the attention direction, no complex filtering needed
- Scenarios with extreme real-time requirements: CDA’s phase determination has latency overhead
4.3 Evaluation Criteria for CDA-Compatible Systems
| Dimension | Metric | Weight | Criterion |
|---|---|---|---|
| Phase awareness | Whether there is an explicit phase state machine | Required | At least distinguish assemble/compact |
| Direction alignment | Whether there is QTS or an equivalent direction scoring mechanism | Required | Retrieval results are sorted by direction |
| Feedback loop | Whether there is miss recording and direction filtering | Required | Historical failures affect subsequent retrieval |
| Dead-End Registry | Whether there is an explicit Dead-End Registry | Required | Known failure directions are filtered at assemble time |
| Topology-preserving compression | Whether fragment relationships are preserved after compression | Bonus | SCG or equivalent implementation |
| Three-layer memory | Whether hot/cold memory are separated | Bonus | Different lifecycle management |
| Hysteresis gate | Whether there is an anti-flicker mechanism | Bonus | Prevents content flashing |
Chapter Summary
This chapter presents 10 design principles for CDA-compatible systems, covering 6 core dimensions:
| Dimension | Core Principle |
|---|---|
| Phase-driven | Must have explicit phase boundaries; phase transitions must be observable |
| Retrieval direction alignment | Must use LLM’s current attention direction as a retrieval dimension |
| Semantic compression | Must preserve semantic topology, not just token truncation |
| Feedback loop | Must have negative filtering mechanism (miss → direction weight adjustment) |
| Dead-End Registry | Must explicitly record and filter disproven reasoning / tool paths |
| QTS configurable | Weights must be tunable, and require scenario-specific tuning |
Value of the SPC-CTX reference implementation: Not “the standard answer,” but “a viable engineering implementation.” SPC-CTX’s 5 core parameters (THRESHOLD_YELLOW=0.70 / RED=0.85 / QTS weights / deltaDirection=0.05 / hot_exp=3) are reference values tuned on real tasks.
Word count for this chapter: ~6,200 words
Chapter 6: The Feasible Path — Design Principles for CDA-Compatible Systems
This chapter is not the SPC-CTX implementation document, but rather the core principles needed to design a CDA-compatible system. SPC-CTX is provided as a reference implementation in the appendix.
5.1 Evaluation Criteria: Is Your System CDA-Compatible?
Before starting design, answer the following questions:
[ ] Can your system distinguish the 5 phases: assemble / ingest / afterTurn / compact / bootstrap?
[ ] Does each phase use a different context assembly strategy?
[ ] When contextUsage > 70%, does your system have a clear response?
[ ] During compression, does your system preserve semantic relationships between fragments?
[ ] Does your system have an explicit Dead-End Registry that filters known bad directions at assemble time?
[ ] Does your memory module expose pluggable APIs (appendTurn / assembleContext / compact / getDirectionState)?If any [ ] is unchecked, your design needs to be strengthened in that direction.
5.2 Phase-Driven Design Principles
Principle 1: Phase transitions are driven by semantic state transitions, not time
Do not use “check every N minutes” to drive phase transitions. Use semantic signals:
// Good design
if (contextUsage > THRESHOLD_RED && currentPhase === 'afterTurn') {
transitionTo('compact');
}
// Bad design
if (elapsedTime > COMPACT_INTERVAL) {
transitionTo('compact');
}Principle 2: Each phase has explicit context entry and exit
| Phase | Entry Condition | Context Source | Exit Condition |
|---|---|---|---|
assemble | User input | Hot memory + retrieval results + skills | LLM output |
ingest | User input complete | Raw messages | Chunking and storage complete |
afterTurn | LLM output complete | Current turn quality metrics | Quality evaluation complete |
compact | contextUsage > THRESHOLD | Current context | Compressed context generated |
bootstrap | System startup | External storage | Initial context ready |
Principle 3: Preserve necessary state across phase transitions
When transitioning from afterTurn to compact, the quality evaluation results accumulated during the afterTurn phase must be passed to compact and not lost.
5.3 Retrieval Direction Alignment Design Principles
Principle 4: QTS’s four dimensions are not fixed, but configurable
The weights of QTS’s four dimensions (intent_match / phase_match / tool_relevance / causal_proximity) should be adjusted according to the specific scenario:
// Code generation scenario
QTS = 0.4×intent_match + 0.1×phase_match + 0.4×tool_relevance + 0.1×causal_proximity
// Medical diagnosis scenario
QTS = 0.5×intent_match + 0.2×phase_match + 0.1×tool_relevance + 0.2×causal_proximity
> **Note**: The above are reference configuration weights, used to illustrate that QTS weights are configurable, and do not represent optimal solutions. In practice, initial values need to be determined through A/B testing based on specific task types, model characteristics, and scenario data, and then iteratively optimized through feedback tuning.Principle 5: Delta Direction thresholds need to be determined experimentally
0.05 is a reference value, but the optimal threshold varies by task type. We recommend determining the optimal threshold through A/B testing.
Principle 6: Build a semantic direction history library
When a direction’s retrieval fails consecutively (miss), that direction should be recorded. The next time a similar direction is encountered, its priority should be reduced in advance.
Weight Tuning Recommendations:
- Derive initial values from task type (code generation: high tool_relevance; medical diagnosis: high intent_match)
- Validate through A/B testing (compare downstream task accuracy under different weight configurations)
- Learn from miss records: if a certain type of miss occurs frequently, check whether the corresponding dimension’s weight is too low
5.4 Compression Design Principles
Principle 7: Preserve semantic topology during compression, not just tokens
// Good design
compressed = compressWithTopology(original_chunks, edge_relationships, target_token_budget)
// Bad design
compressed = summarizer.compress(original_text, target_token_budget)Principle 8: Introduce hysteresis gates to prevent content flickering
// Hysteresis gate implementation
if (currentZone === 'keep' && newScore < KEEP_THRESHOLD - HYSTERESIS) {
transitionTo('compress'); // score must drop below KEEP_THRESHOLD plus hysteresis to switch
} else if (currentZone === 'compress' && newScore > KEEP_THRESHOLD + HYSTERESIS) {
transitionTo('keep'); // score must rise above KEEP_THRESHOLD plus hysteresis to switch
}Principle 9: Causal chain protection
If a fragment has been marked for dropout for N consecutive turns, it is forcibly moved to the compress region on the (N+1)th turn, preventing critical reasoning chains from being accidentally truncated. A typical value for N is 3.
5.5 Feedback Loop Design Principles
Principle 10: Hot experience discovery triggers must be quantified
Hot experience = same tool-feature combination
× hitCount ≥ 3
× stdDev(alignment_scores) < 0.15
× recency < 7daysDo not use vague “high-frequency experience” judgments. They must be quantified.
Principle 11: Skill formal interfaces must be independent of specific implementations
Skill storage format must be system-agnostic so it can migrate between different systems:
Skill:
id: string
preconditions:
phase: enum
evidence: array
execution_pattern:
steps: array
transitions: map
boundaries:
valid_conditions: array
invalid_conditions: array
outcome_tags:
success_patterns: array
failure_patterns: array# Example: Skill for code refactoring task
Skill:
id: "code_refactor_v1"
preconditions:
phase: "assemble"
evidence: ["user requests refactoring", "existing code snippet"]
execution_pattern:
steps: ["analyze existing structure", "identify refactor points", "generate refactoring plan"]
transitions:
after_analysis: "identify_refactor_points"
boundaries:
valid_conditions: ["complete code available", "clear refactoring goal"]
invalid_conditions: ["incomplete code", "vague refactoring goal"]
outcome_tags:
success_patterns: ["functionality unchanged after refactoring", "lines of code reduced"]
failure_patterns: ["introduced new bug", "missing functionality after refactoring"]5.6 SPC-CTX Reference Implementation
The following is an abstract description of SPC-CTX’s key design decisions, serving as a reference implementation rather than engineering detail:
Architectural Decision 1: Phase-driven + Passthrough dual-mode design
SPC-CTX enters passthrough mode during bootstrap if messageStore is empty — all messages are poured directly into LLM context. This is necessary because the first few turns after session restart cannot rely on cold memory. Passthrough is not a bug, but a design choice to ensure the session does not “forget” after restart.
Architectural Decision 2: Decoupling compact write / assemble read
compact and assemble are two independent phases sharing a context_items interface:
compact() → writes context_items (compact curated set)
assemble() → reads context_items (not full messages)This decoupling allows compact and assemble to evolve and be tested independently.
Architectural Decision 3: Two-layer token estimation
| Estimation Layer | Counting Scope | Purpose |
|---|---|---|
| SPC-CTX layer | SQLite message_parts | Drives compact triggers |
| Gateway layer | Current session raw JSONL | User-visible metric |
The difference between the two layers is about 4.8% (SPC-CTX underestimates), because SPC-CTX does not count system prompts, tool definitions, or workspace file injections. This is not a bug, but a difference in measurement dimensions.
5.7 Pluggable Memory Backend Interface Design Principles
To allow SPC-CTX to be dropped into other Agent frameworks as a replacement memory module, a minimal API surface must be exposed:
// Append one turn plus tool trace
appendTurn({ messages: Message[], tools: ToolCall[], phase: Phase })
// Assemble the minimal context needed for this turn
assembleContext({
query: CurrentIntent,
max_tokens: number
}) => AssembledContext
// Trigger compression on demand
compact({ strategy?: 'auto' | 'aggressive' })
// Inspect semantic direction state (for debugging / monitoring)
getDirectionState() => {
global_intent: IntentVector,
drift_score: number,
dead_end_matches: DeadEndMatch[]
}
// Explicitly register a dead-end (negative experience)
registerDeadEnd({ session_id: string, trace: object, reason: string })Principle 12: Memory backend interfaces must be independent of any specific LLM or framework
Do not let assembleContext return framework-specific data structures. It should return a standard { messages: Message[], metadata: ContextMeta }, leaving the caller to wrap it into OpenAI, Claude, or LangChain input formats.
Principle 13: The interface semantics are “direction state machine,” not “storage warehouse”
getDirectionState returns the current deviation from global intent, not “what is remembered.” This lets external systems monitor whether an Agent is gradually drifting off course during long sessions.
Chapter Summary
This chapter presents 13 design principles for CDA-compatible systems, covering phase-driven, retrieval direction alignment, compression, feedback loops, and pluggable interfaces.
The three most important principles:
- Principle 1: Phase transitions are driven by semantic state transitions, not time — this is the most easily overlooked design decision
- Principle 5: CDA’s guarantee is negative, not positive — do not try to guarantee finding the right direction, but guarantee not repeating a dead end
- Principle 10: Hot experience discovery triggers must be quantified — hitCount ≥ 3 and stdDev < 0.15, rejecting subjective judgment
SPC-CTX as reference implementation: Appendix A provides the complete SPC-CTX architecture, parameters, and version history.
Chapter 5: Competitive Landscape and Moat
6.1 The Common Blind Spot of Existing Solutions
| System | Core Focus | CDA Differentiation |
|---|---|---|
| MemGPT | Hierarchical storage (OS virtual memory analogy) | No phase-aware, no direction alignment |
| Zep | Episodic memory + knowledge graph | Focuses on “what to store” (entity relations), not “when to retrieve” |
| LangChain Memory | Conversation buffer + summary | No semantic direction alignment, no phase distinction |
| RAG | Text similarity retrieval | Retrieval direction ≠ LLM attention direction |
| Claude Context Editing | Automatic context editing | Commercial implementation, not open source |
Common blind spot: all existing systems answer the question “What if there’s too much context?” but no system systematically answers “At what timing, in what direction, should what information be retrieved?“
6.2 Moat Analysis of the CDA Paradigm
Algorithm Layer: CDA does not have proprietary algorithms. All core algorithms (vector retrieval, hierarchical memory, semantic compression) can be found in academic literature.
Combination Layer: CDA’s moat lies in the combination of Phase × QTS × SCG × three-layer memory. LangChain/LlamaIndex’s phase concept is coarse-grained (only before/after), while CDA’s Phase is semantic-level (5 phases each with different retrieval strategies). This granularity difference requires extensive experimentation to discover.
Engineering Art Layer: CDA’s moat lies in the accumulated knowledge of “what not to do.” 0% self_tag response rate, compact results not being read, QTS parameters without experimental validation — these “do nots” are accumulated from real failures, not designed. The real moat is not the algorithm formula, but the tuning experience of “how not to break the protocol.”
Productization Layer: The protocol and design documents remain open (CC BY-ND 4.0), but the industrial-grade implementation — tuning strategies, graph-compression details, Dead-End Registry matching thresholds, multi-tenant deployment experience — forms the value of a closed-source or enterprise offering. The free edition provides local APIs; the enterprise edition adds monitoring dashboards, drift alerts, and multi-tenant support.
Paradigm Layer: CDA’s identity as “the first to establish a context management paradigm framework” is the most durable and also the most fragile moat. Durable because the paradigm founder’s identity cannot be copied; fragile because the paradigm itself can be learned.
6.3 Positioning of SPC-CTX
SPC-CTX (product name: Direction-Preserving Context Engine) is the reference implementation of the CDA paradigm, not the CDA paradigm itself.
This means:
- SPC-CTX / Direction-Preserving Context Engine will become outdated (as hardware/models/scenarios evolve)
- But the CDA paradigm as a theoretical framework can guide other implementations
This is why “Context Direction Alignment: The Core Paradigm for AI Agent Context Management” has more strategic value than “SPC-CTX Technical Documentation.”
The manuscript establishes paradigm authority, not product documentation.
Chapter Summary
This chapter analyzes CDA paradigm’s position in the competitive landscape and sources of moat.
Core finding: all existing systems (MemGPT / Zep / LangChain / LlamaIndex) answer the “what to store” question — their differentiation lies in what content to store. CDA answers “when to retrieve + what direction to retrieve” — this is a fundamental paradigm difference.
Positioning of SPC-CTX: not competing with existing frameworks, but carving out a new technical position — “Context Engineering” — a third path beyond RAG and Memory.
Chapter 7: Technical Debt and Future Directions
7.1 Current Technical Debt
| Issue | Impact | Priority |
|---|---|---|
| Embedding API dependency | Embedding quality affects overall effectiveness | 🟡 P1 |
| No benchmark for compact algorithm | Compression quality cannot be quantitatively evaluated | 🟡 P1 |
| Metrics and benchmarks | Reproducible benchmarks for Alignment Stability / Dead-End Repetition Rate / ECD are incomplete | 🔴 P0 |
7.2 Open Research Directions
Direction 1: Joint optimization of CDA with model-native attention mechanisms
Current CDA filters context outside the model. If CDA’s direction signals could be passed to the model’s attention layer, more precise context utilization might be achieved.
Direction 2: CDA extension in multi-Agent scenarios
In multi-Agent collaboration, each Agent has its own attention direction. How to share context between Agents while maintaining each Agent’s semantic direction independence is an open problem.
Direction 3: Quantifiable evaluation metrics for CDA
Currently CDA’s effectiveness is mainly measured by downstream task accuracy, lacking an independent industry-standard metric. This book has proposed three core metrics (Alignment Stability, Dead-End Repetition Rate, Effective Context Density). The next step is to build reproducible benchmarks and a public leaderboard.
Conclusion
CDA is not a feature, but a perspective shift.
From “How to fit more information into a limited window,” to “With only 10% of historical context retained, how do we keep the Agent’s direction from drifting and ensure dead ends are not repeated?”
The former is a storage problem; the latter is a direction problem.
The solution to a storage problem is to keep expanding capacity (but demand always outpaces growth). The solution to a direction problem is precise alignment and negative filtering (capacity is compressed, stability improves).
CDA chooses the latter — not because capacity is unimportant, but because direction is scarcer than capacity. What truly matters is not “how much is remembered,” but “which paths have already been proven wrong.”
This document is written based on Wilson/Blitz’s real engineering practice, SPC-CTX development experience, and real session runtime data (intensive period April 2026).
Appendix A: SPC-CTX Reference Implementation
A.1 Architecture Overview
User input
↓
[Phase determination] → inferPhase(rawIntent, recentTools)
↓
[Direction calculation] → deltaDirection(prev, curr) → DirectionVector
↓
[Assembly phase]
├─ basicAssemble (no snapshot)
└─ fullAssemble (with snapshot) → QTS scoring → keep/compress/dropout
↓
[Compression phase] → SCG Semantic Compression → [Compressed] tag
↓
[Alignment evaluation] → computeAlignment(direction, scores)
↓
[Hot experience discovery] → discoverHotExperiences (hitCount ≥ 3, stdDev < 0.15)
↓
LLM ContextA.2 Core Parameter Reference
DELTA_THRESHOLD = 0.05 // direction shift detection threshold
KEEP_THRESHOLD = 0.75 // keep/compress boundary
COMPRESS_THRESHOLD = 0.25 // compress/dropout boundary
HYSTERESIS_MARGIN = 0.10 // hysteresis gate margin
CAUSAL_CHAIN_N = 3 // consecutive dropouts triggering forced compress
HOT_EXPERIENCE_HITCOUNT = 3 // minimum hit count for hot experience
HOT_EXPERIENCE_STDDEV = 0.15 // maximum standard deviation for hot experienceA.3 SPC-CTX Version History
| Version | Key Changes |
|---|---|
| v0.10.x | Introduced compact sidecar mode |
| v0.13.0 | Three-layer memory architecture established |
| v0.15.x | QTS formalization introduced |
| v0.16.0 | P0 Bug Fix: assemble finally reads context_items, compact no longer runs for nothing |
A.4 Current Runtime Status (2026-04-13)
SPC-CTX version: v0.16.0
messages table: 1287 items, 611K tokens
context_items: 90 items (compact curated set)
QTS scoring: active (compact subset, 90 items)
last compact: 2026-04-13 16:04 CSTA.5 Minimal External API (v1.1.0+)
// Append one turn plus tool trace
appendTurn({ messages: Message[], tools: ToolCall[], phase: Phase })
// Assemble the minimal context needed for this turn
assembleContext({
query: CurrentIntent,
max_tokens: number
}) => AssembledContext
// Trigger compression on demand
compact({ strategy?: 'auto' | 'aggressive' })
// Inspect semantic direction state (for debugging / monitoring)
getDirectionState() => {
global_intent: IntentVector,
drift_score: number,
dead_end_matches: DeadEndMatch[]
}
// Explicitly register a dead-end (negative experience)
registerDeadEnd({ session_id: string, trace: object, reason: string })
// List known dead ends (for debugging / UI display)
listDeadEnds({ session_id: string, top_k?: number }) => DeadEndItem[]Appendix B: Glossary
| Term | Symbol | Definition |
|---|---|---|
| Semantic Direction | D | The region of semantic space to which LLM attention currently points |
| Semantic Gradient | G = dD/dt | The rate of change of semantic direction |
| Direction Alignment | ⟨D_target, D⟩ | Cosine similarity between target direction and current direction |
| QTS Score | QTS(m, D) | Relevance score of message m relative to direction D |
| Phase | p ∈ {A, I, T, C, B} | Agent behavioral phase (assemble/ingest/afterTurn/compact/bootstrap) |
| Hysteresis Gate | H | Mechanism to prevent score oscillation from causing content flickering |
| Causal Chain Protection | N | After N consecutive dropouts, force compress; N=3 |
| Dead-end Recording | miss | A thesis/evidence chain direction that has been falsified |
| Filtering Gradient | decay | Subsequent weight decay caused by miss history |
| Hot Experience | hot | A stable success pattern with hitCount ≥ 3 and stdDev < 0.15 in the same direction |
| Cold Experience | cold | Experience that has not yet reached hot experience criteria |
| SCG | Semantic Context Graph | Compression algorithm that preserves semantic topological structure |
| SPC-CTX | Semantic Phase Context | Reference implementation of the CDA paradigm |
| CDA | Context Direction Alignment | The core of the CDA paradigm |
| Direction-Preserving Context Engine | — | The product name for the CDA paradigm |
| Dead-End Registry | — | Negative-experience store that records disproven reasoning chains / tool-call patterns |
| Alignment Stability | — | Directional stability: how semantic similarity between current direction and global intent evolves across turns |
| Dead-End Repetition Rate | — | The proportion of already-disproven strategies that are retried in subsequent turns |
| Effective Context Density (ECD) | — | The ratio of historically useful information successfully used for reasoning to total tokens fed |